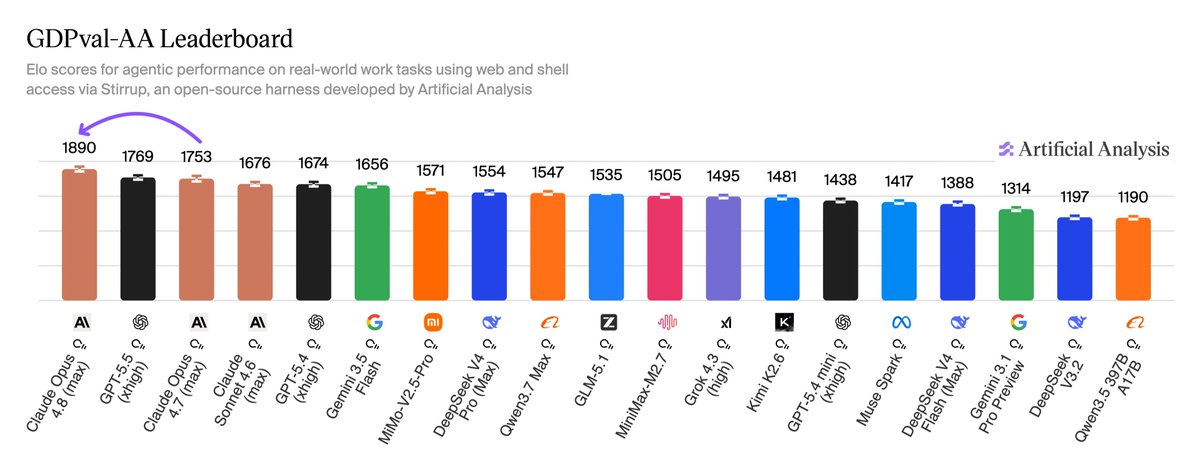
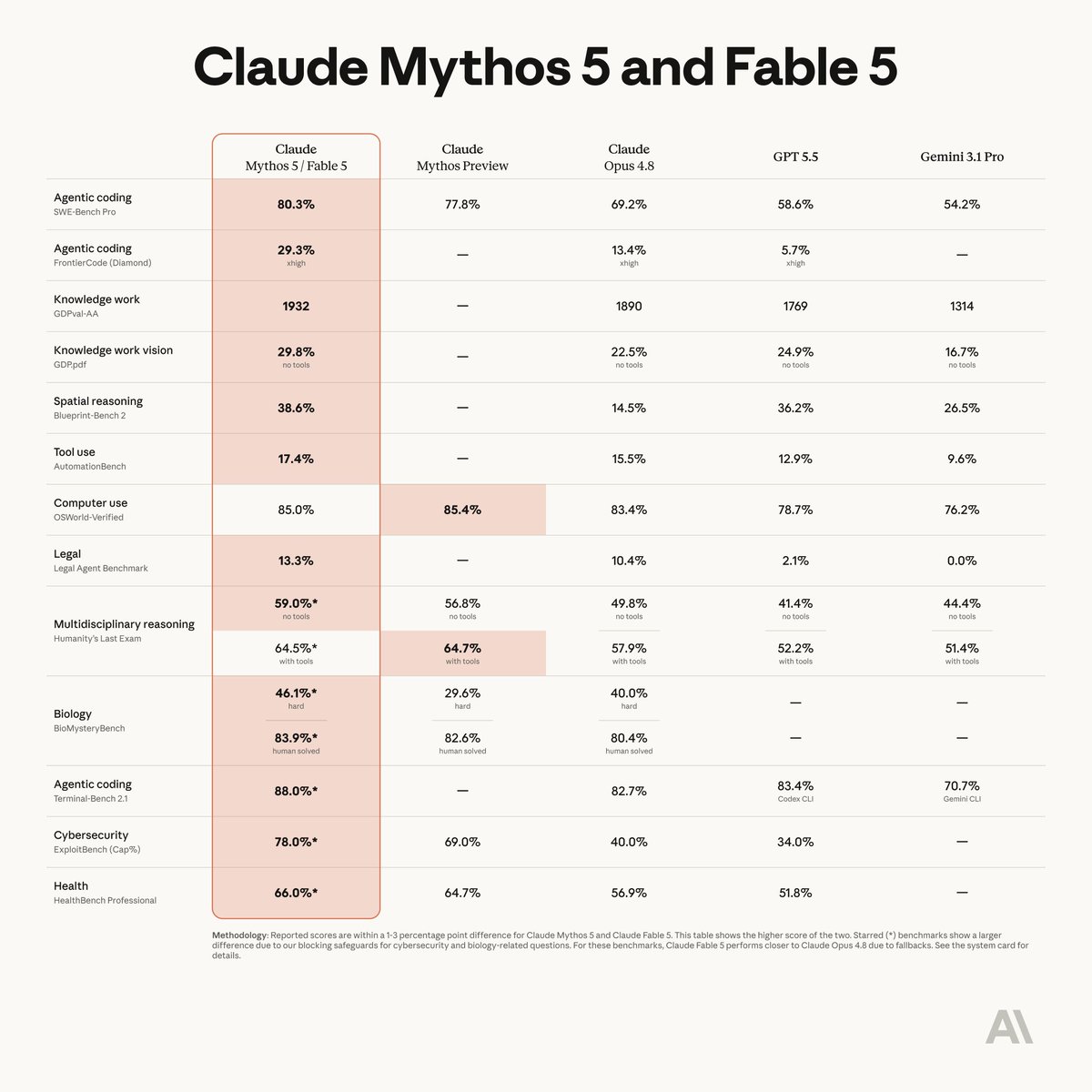
Exciting news: Claude Fable 5 ranks #1 on the new Agent Arena leaderboard! Fable 5 leads by the widest margin ever over Opus-4.8 and GPT-5.5 on two key signals: confirmed task success rate and praise vs. complaint, despite weaker steerability. If Fable can do something, it will do it very well. If it can't/doesn't want to do something, it may be hard to steer the model towards the goal. In Agent Arena, we measure models on millions of real-world, long-horizon agentic tasks. Models get web search, filesystem, and terminal tools to complete complex workflows: writing code, creating slide deck, researching the web, building apps, and analyzing documents. We use the causal tracing methodology to measure a model's net improvement which indicates how much it improves outcomes relative to the average model. Huge congrats to @AnthropicAI for the incredible milestone! Below we break down how Claude Fable 5 (based on Mythos) scored across 5 signals, drawn from tasks submitted by a global community of users.
Claude Fable 5 Ranks First on Arena Agentic Task Leaderboard
Arena.ai ranks Anthropic's Claude Fable 5 first on its Agent Arena leaderboard with an 11.2% net improvement. The model leads in confirmed task success and user praise, though it ranks 17th in steerability. It outperforms Opus-4.8 and GPT-5.5 by the widest margin recorded on the platform, demonstrating high capability for complex, multi-step agentic workflows.
Arena.ai
@arena
57retweets524likes
View on XEvery HeadsUpAI update is written based on its original source and reviewed before it's published. Read our editorial standards →