Trip Venturella released Mr. Chatterbox, a 340-million parameter language model trained exclusively on 28,000 Victorian-era British texts from the 19th century. While the model captures a historical persona, its limited 2.93 billion token dataset highlights the performance gap between public domain training and modern web-scraped models.
Trip Venturella developed Mr. Chatterbox, a 340-million parameter language model trained from scratch using Andrej Karpathy's nanochat architecture. The training corpus consists of 2.93 billion tokens from out-of-copyright British Library texts published between 1837 and 1899, ensuring no modern data influenced the model's vocabulary or logic.
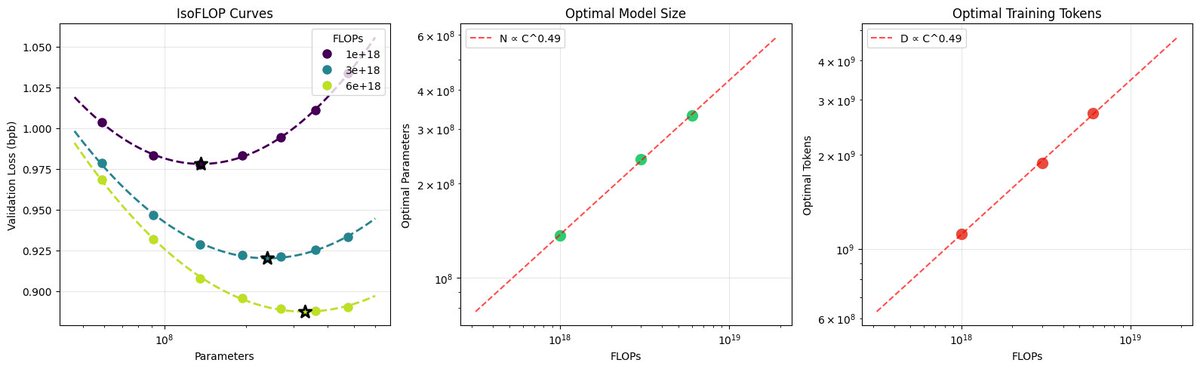
This project serves as a benchmark for ethically trained models using only public domain data. Testing shows the model behaves more like a Markov chain than a modern assistant, reinforcing Chinchilla scaling laws which suggest a 340M parameter model requires 7 billion tokens to achieve conversational utility.
You can run the 2.05GB model locally using the llm-mrchatterbox plugin for the llm CLI tool. The command uvx --with llm-mrchatterbox llm chat -m mrchatterbox initiates a session. Developer Simon Willison used Claude Code to autonomously build the plugin and wrap the model for local execution.