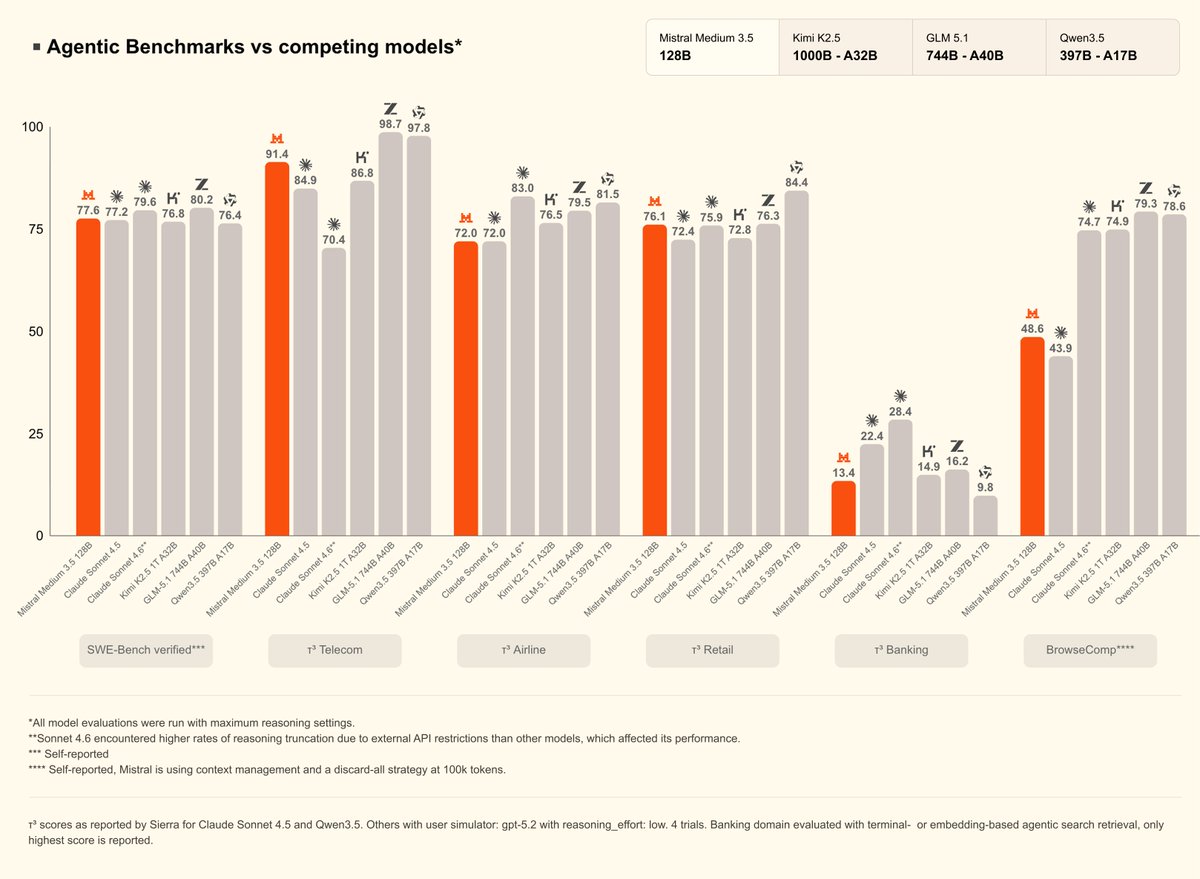
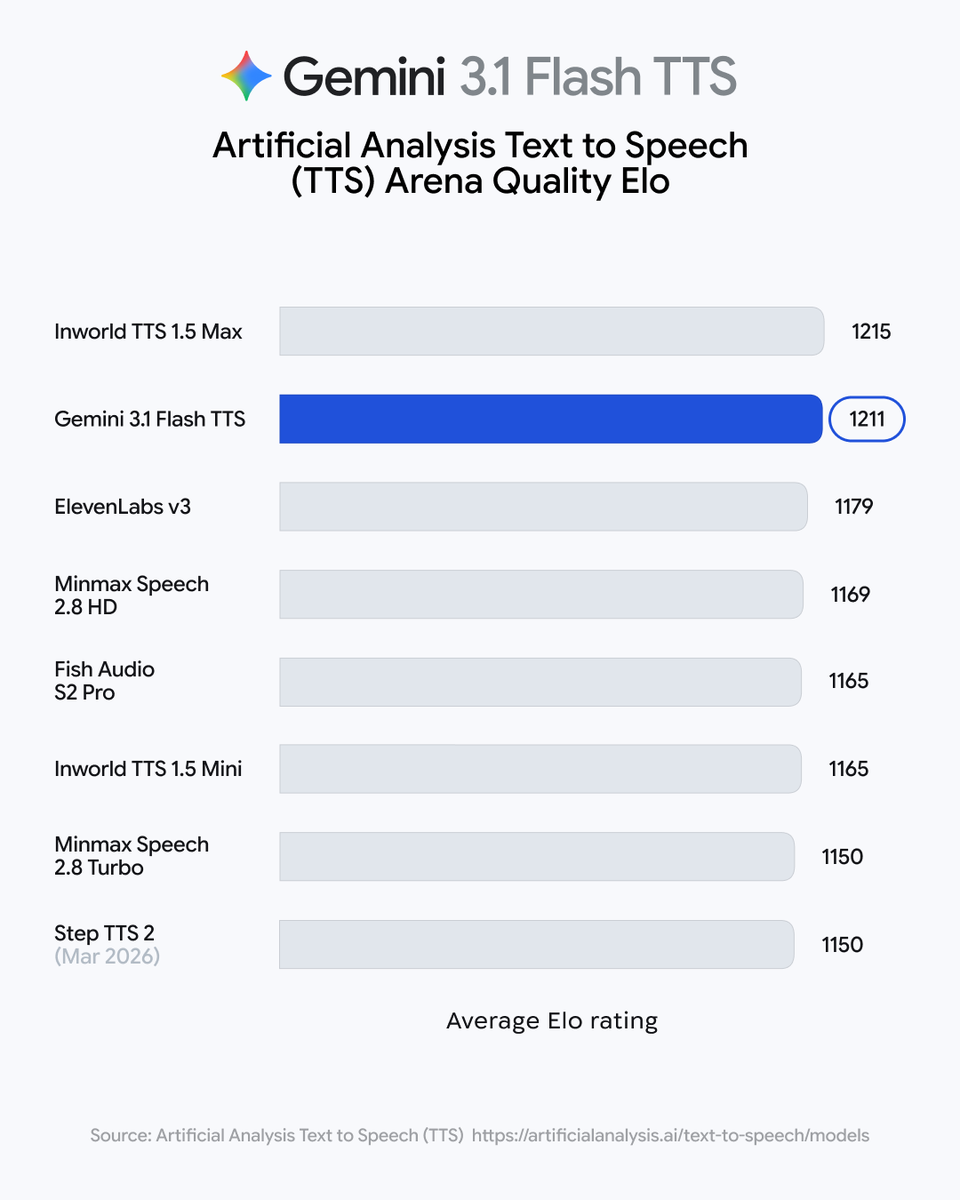
Mistral AI launched Voxtral TTS, a 4B-parameter text-to-speech model capable of zero-shot voice cloning from just three seconds of audio. By offering frontier-grade emotional expressiveness and low latency in an open-weight format, it provides a high-performance alternative to closed-source providers for building real-time voice agents.
Mistral AI launched Voxtral TTS, a 4B-parameter model designed for natural, expressive speech. Built on the Ministral 3B backbone, the architecture combines a 3.4B decoder with a 390M flow-matching acoustic transformer and a 300M neural audio codec. It supports nine languages and captures subtle nuances like rhythm, intonation, and regional dialects.
The model addresses the latency-quality trade-off critical for voice agents, achieving a 70ms model latency. It matches the quality of proprietary leaders like ElevenLabs while enabling zero-shot cross-lingual adaptation. This allows a speaker's unique voice and accent to be preserved when generating speech in a different language.
You can access Voxtral TTS via API at $0.016 per 1,000 characters or test it in Mistral Studio. An open-weight version is available on Hugging Face under a CC BY NC 4.0 license. This enables cost-effective, localized voice workflows for customer support and real-time translation.