Google DeepMind
@GoogleDeepMind
Gemini 3.1 Flash TTS is our most controllable text-to-speech model yet. With new Audio Tags, you can easily direct vocal style, delivery, and pace through text commands. 🧵
111retweets1klikes
View on X· Updated
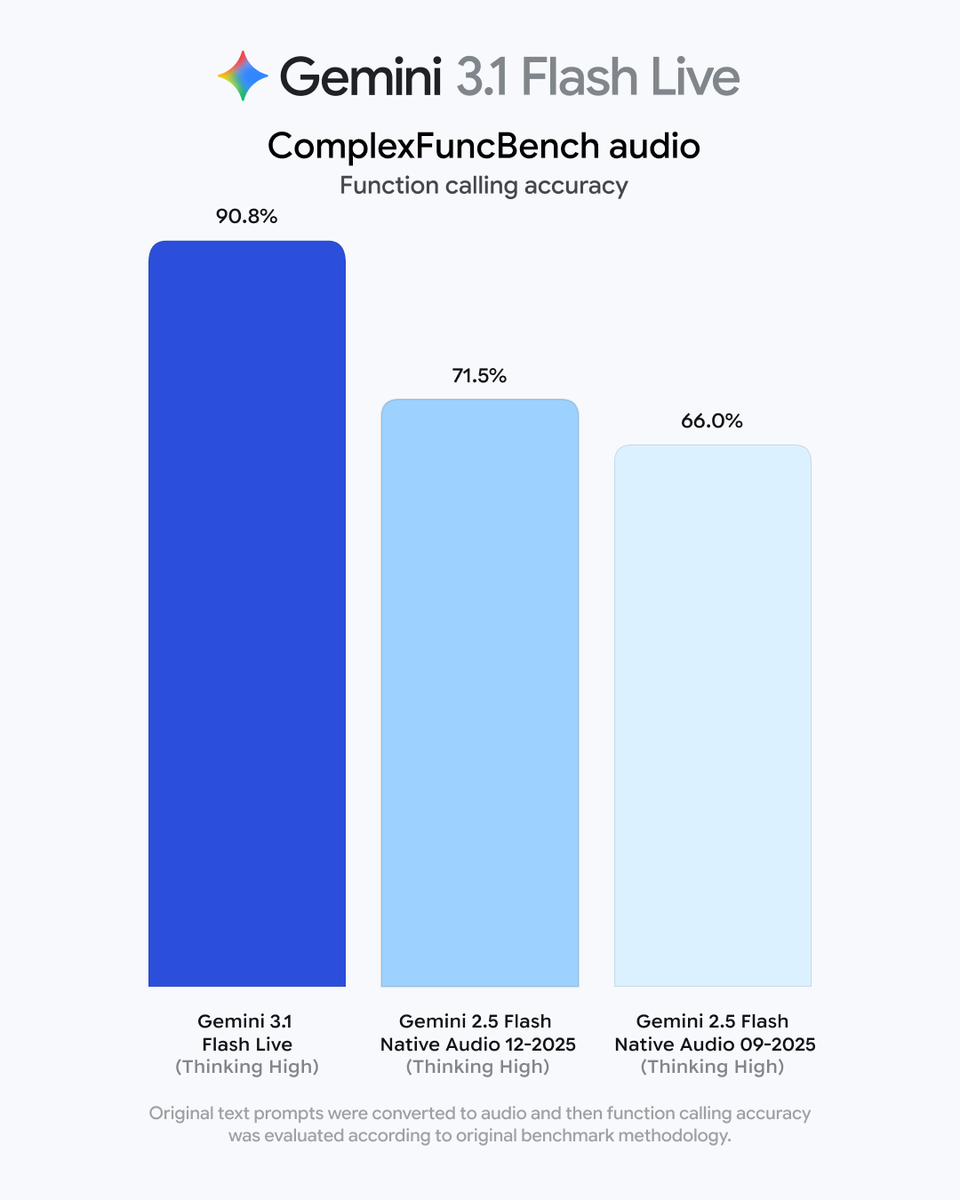
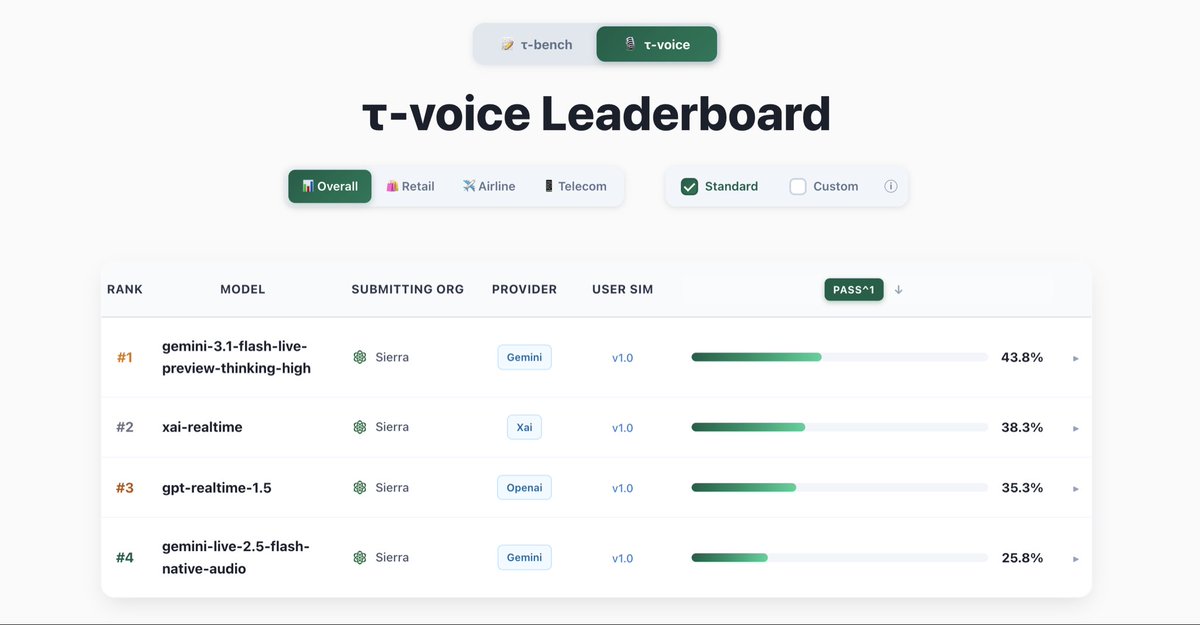
Google released Gemini 3.1 Flash TTS, a text-to-speech model that uses natural language audio tags to control vocal style, pace, and delivery. This update allows users to direct AI speech like a human performance while maintaining low costs and high speed.
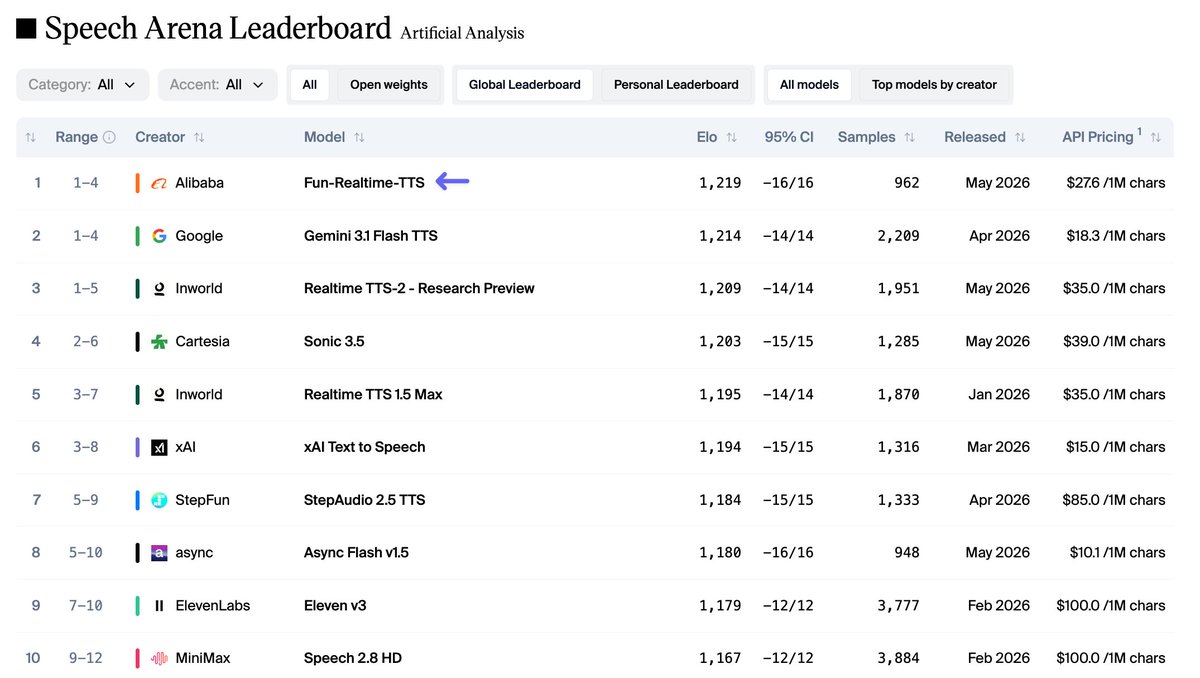
Traditional text-to-speech often requires complex markup or produces robotic results. By moving control to natural language, this model lowers the barrier for creating immersive voice experiences. It currently leads the Artificial Analysis TTS leaderboard for its balance of high-quality human preference scores and low inference (running a trained model) costs.
Access the model in preview through the Gemini API and Google AI Studio, which features a "Director's Chair" interface for scene direction. Enterprise users can find it on Vertex AI, while Workspace users will see it rolling out in Google Vids for automated video voiceovers.
Gemini 3.1 Flash TTS is our most controllable text-to-speech model yet. With new Audio Tags, you can easily direct vocal style, delivery, and pace through text commands. 🧵
Every HeadsUpAI update is written based on its original source and reviewed before it's published. Read our editorial standards →
More like this