Google DeepMind
@GoogleDeepMind
Say hello to Gemini 3.1 Flash Live. 🗣️ Our latest audio model delivers more natural conversations with improved function calling – making it more useful and informed. Here’s what’s new 🧵
183retweets
View on X· Updated
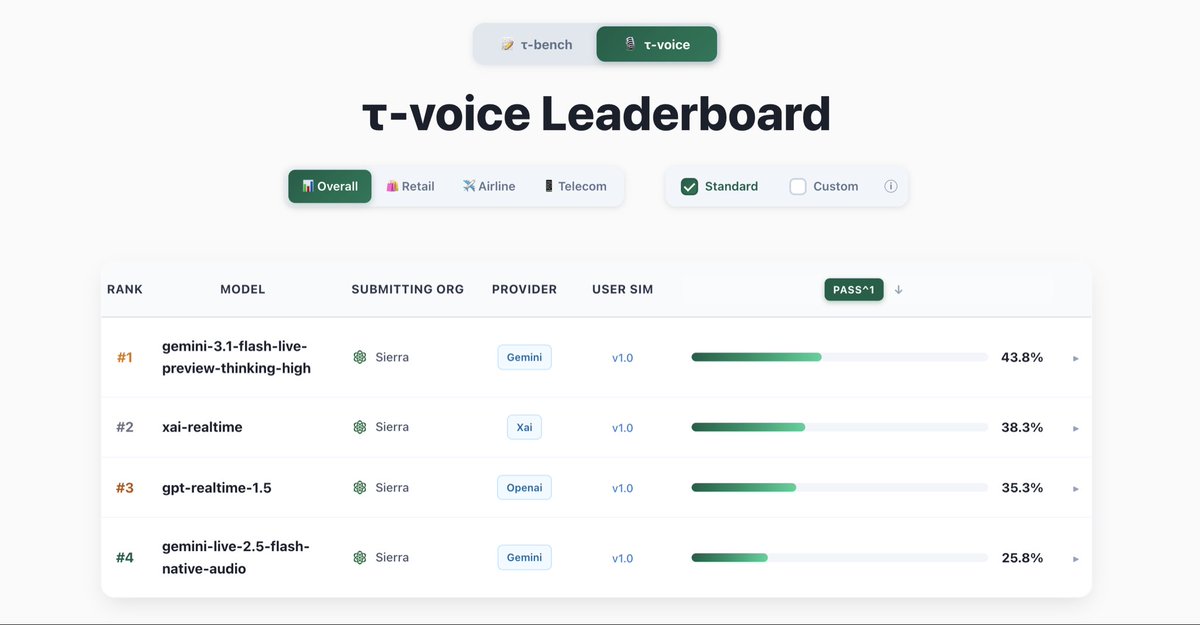
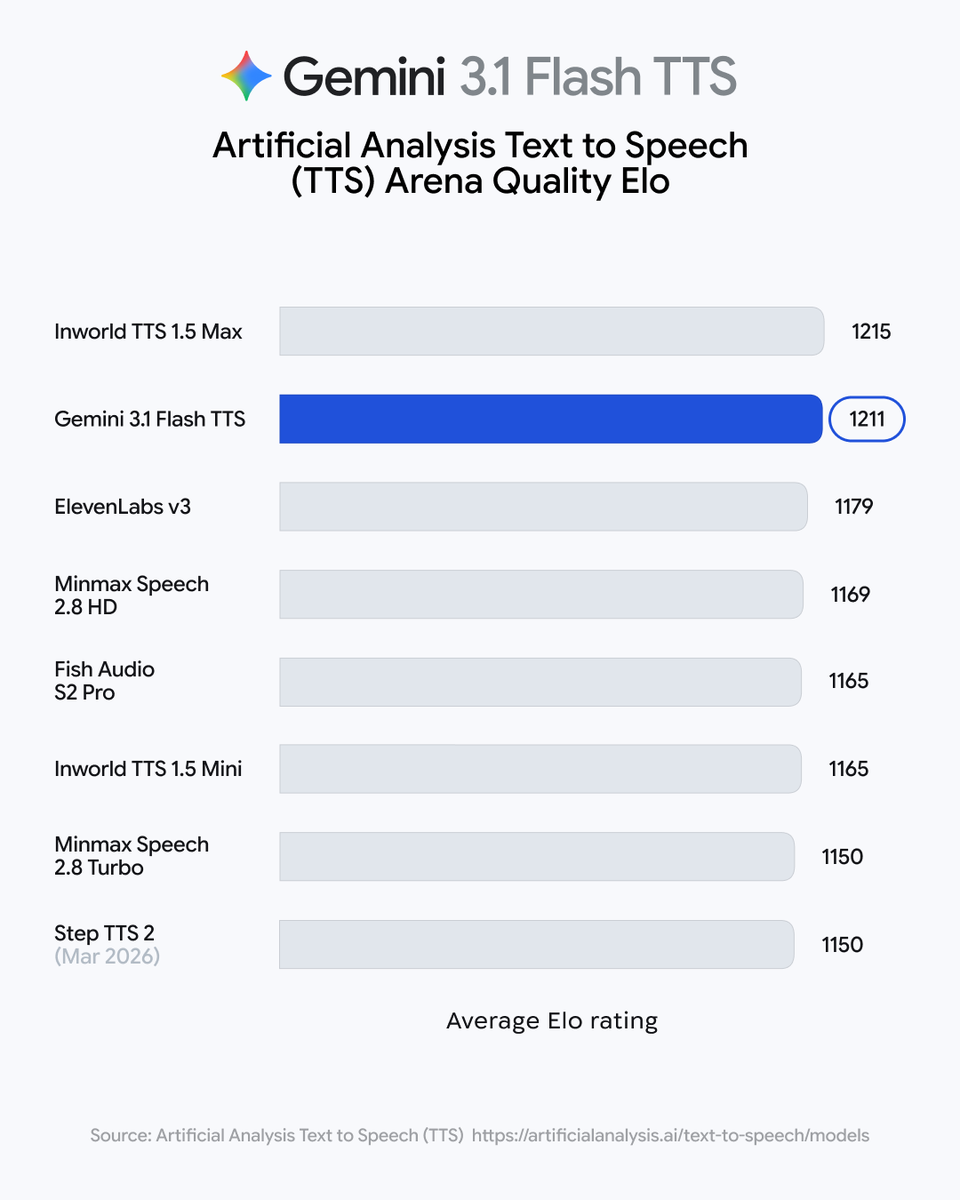
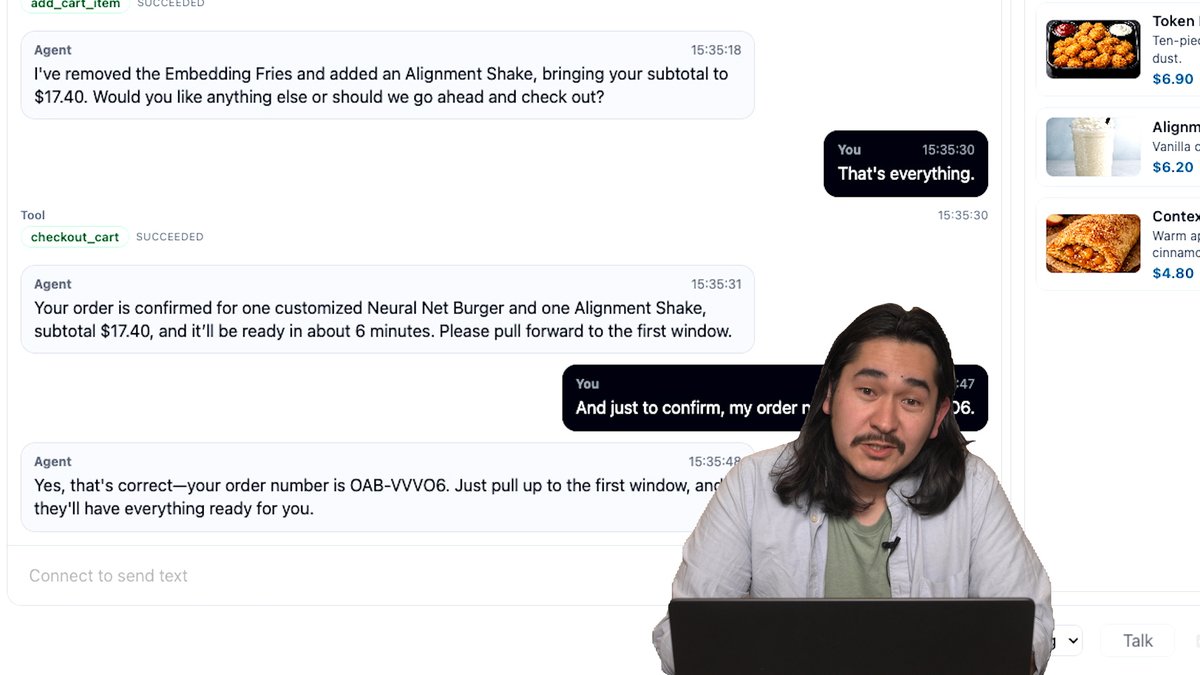
Google DeepMind released Gemini 3.1 Flash Live, a low-latency audio model optimized for real-time dialogue and complex task execution. The model improves function calling and tonal recognition, allowing voice agents to handle multi-step workflows and emotional nuances more reliably. This enables more fluid interactions in noisy environments without losing conversational context.
ComplexFuncBench Audio benchmark, indicating a major leap in multi-step function calling. The model also includes improved tonal understanding to detect pitch, pace, and user frustration during live interactions.Most voice interfaces struggle with interruptions, background noise, and long-term context. This update doubles the conversation thread length, allowing the AI to maintain a train of thought during extended brainstorms. By processing audio natively rather than converting to text first, it reduces latency and captures acoustic nuances that text-only models miss.
You can access the model in preview via the Gemini Live API in Google AI Studio to build low-latency voice agents. It is also integrated into Gemini Enterprise for Customer Experience for automated support. All generated audio is protected by SynthID watermarking to help identify AI-generated content across 200 countries.
Say hello to Gemini 3.1 Flash Live. 🗣️ Our latest audio model delivers more natural conversations with improved function calling – making it more useful and informed. Here’s what’s new 🧵
Every HeadsUpAI update is written based on its original source and reviewed before it's published. Read our editorial standards →
More like this