Google AI Developers
@googleaidevs
Gemini 3.1 Flash TTS is our most expressive speech generation model to date. [excited] Watch this demo from @thorwebdev ⬇️
14retweets226likes
View on X· Updated
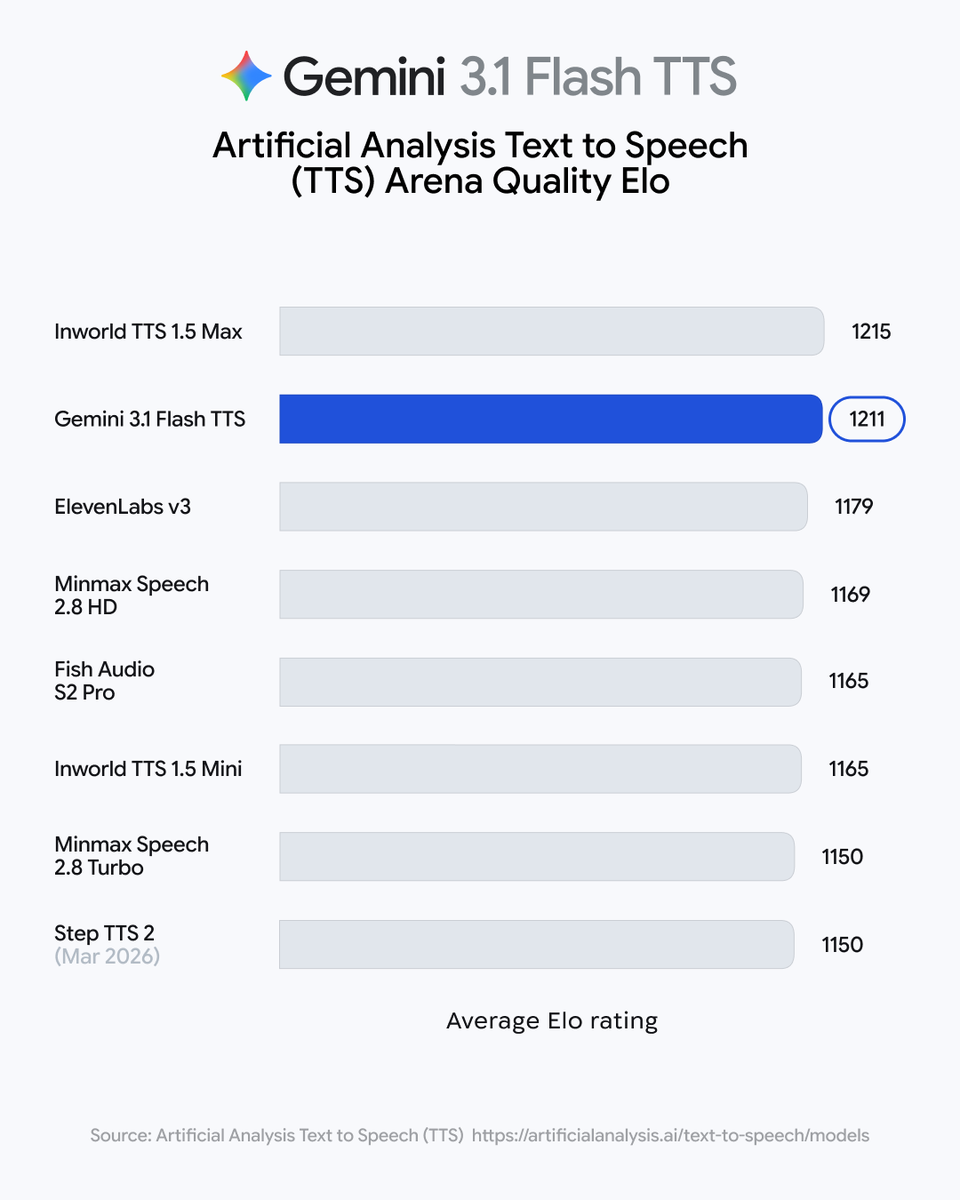
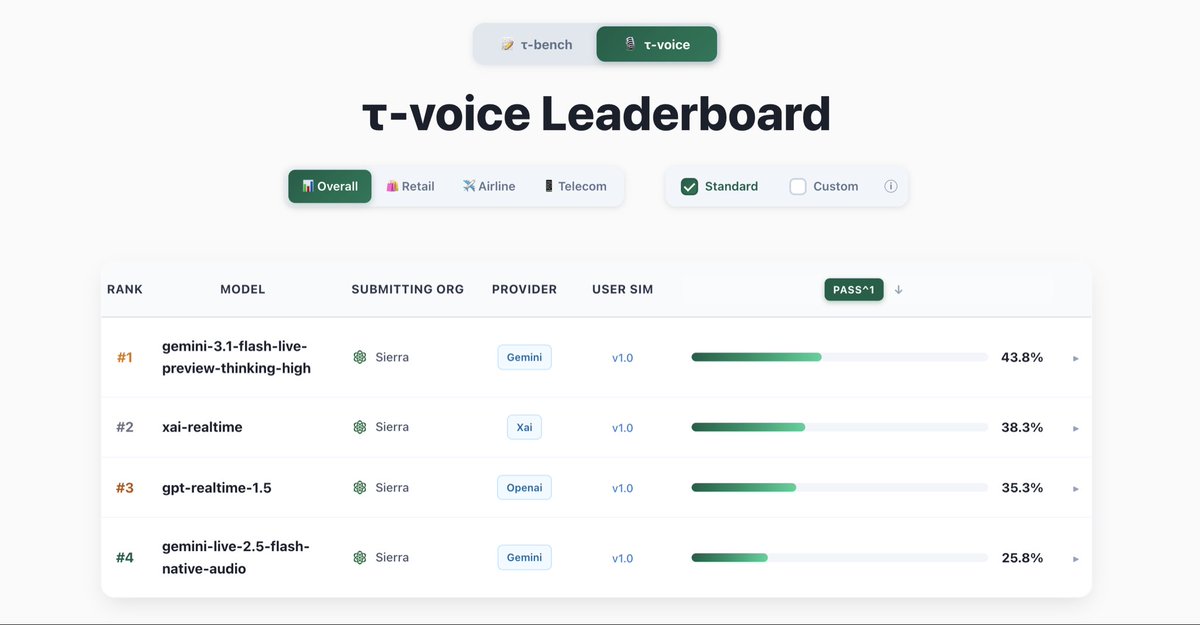
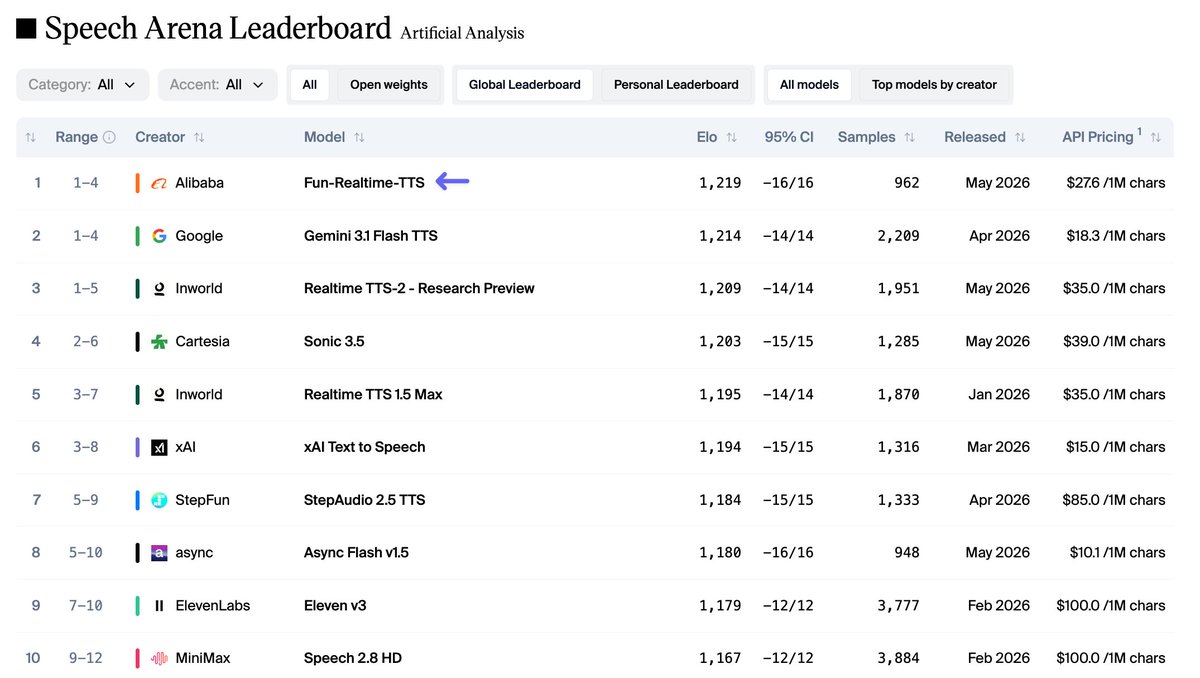
Google designated Gemini 3.1 Flash TTS as its most expressive speech generation model to date. The model uses natural language audio tags to allow developers to direct emotional delivery and vocal character within generated audio.
[excited]—to give users direct control over the emotional tone and performance of the output. This builds on the initial audio tag framework released earlier this month.The update highlights a shift toward directable AI audio that can mimic human performance nuances like pace and character. By using the Flash architecture, the model maintains the speed required for real-time applications while expanding its expressive range. This follows the optimization of agentic workloads using specialized multimodal models.
Use the model to generate speech requiring specific tonal direction for storytelling or interactive agents. The system integrates these vocal cues into text prompts, following the formal prompting framework for syntax and constraints. These capabilities are available through the standard developer platforms used for the Gemini model family.
Gemini 3.1 Flash TTS is our most expressive speech generation model to date. [excited] Watch this demo from @thorwebdev ⬇️
Every HeadsUpAI update is written based on its original source and reviewed before it's published. Read our editorial standards →
More like this