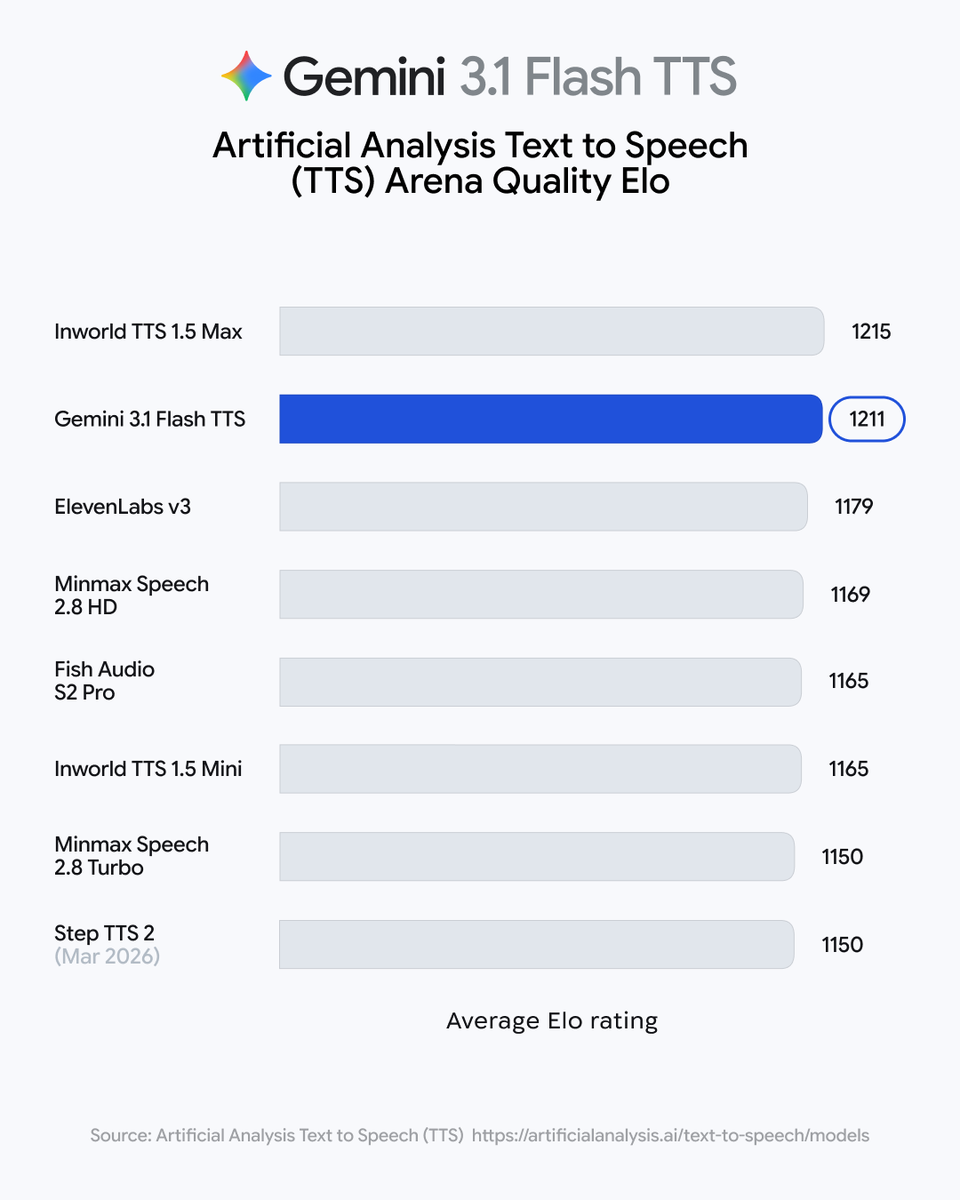
Last week, we launched Gemini 3.1 TTS, our latest and best text-to-speech model. This new model introduces [awe] audio tags, an intuitive way to guide vocal style, pace, and delivery. Here are some tips on the best ways to use audio tags in your prompts: 1. All inline tags must be enclosed in square brackets, such as [screams] or [whispers] 2. Insert these tags exactly where you want the transition to occur and make sure to avoid placing tags directly next to each other 3. Use tags like [slow] or [fast] to control the pace of the delivery, or even [short pause] or [long pause] to ramp up the anticipation in dramatic moments 4. The model also offers granular control over vocalizations, allowing you to direct the delivery with cues like [cackles] or [whispers] 5. An ideal audio tag formula could look something like: [encouraging] Let’s try that last sentence again to make sure that you nailed it. [slow] "L'oiseau s'est envolé." [short pause] Perfect! [laughs] You're a natural. No matter what you’re developing — from [scholarly] a language learning tool, to [mysterious] an interactive podcast app, to [friendly] more adaptive customer service offerings, and beyond — these prompting tips will equip you to start building with Gemini 3.1 TTS.
Google Releases Prompting Formula for Granular Control of Gemini 3.1 TTS
· Updated
Google released a formal prompting framework for Gemini 3.1 TTS that uses inline audio tags to control speech style and pacing. This update provides the specific syntax and constraints needed to direct AI voices like human actors, enabling dynamic and expressive vocal performances.
- Syntax
- Square brackets
- Placement
- Inline at transition point
- Pacing tags
- slow, fast
- Pause tags
- short pause, long pause
- Vocalization tags
- whispers, cackles, laughs, screams
- Style tags
- encouraging, scholarly, mysterious, friendly
- Availability
- Gemini 3.1 TTS via Gemini API
Traditional text-to-speech often relies on global settings that apply one emotion to an entire text block. These syntax rules enable precise word-level transitions, allowing a single output to shift from a whisper to a cackle. This precision extends the utility of Google's production-grade voice agents.
You can direct performances by inserting tags like [slow] or [short pause] exactly where transitions occur. The model supports vocalizations like [laughs] and stylistic cues like [scholarly], provided tags are not placed directly next to each other. This builds on the model's status as a leader in expressive speech generation for language learning and customer service.
Still wondering? A few quick answers below.
Every HeadsUpAI update is written based on its original source and reviewed before it's published. Read our editorial standards →