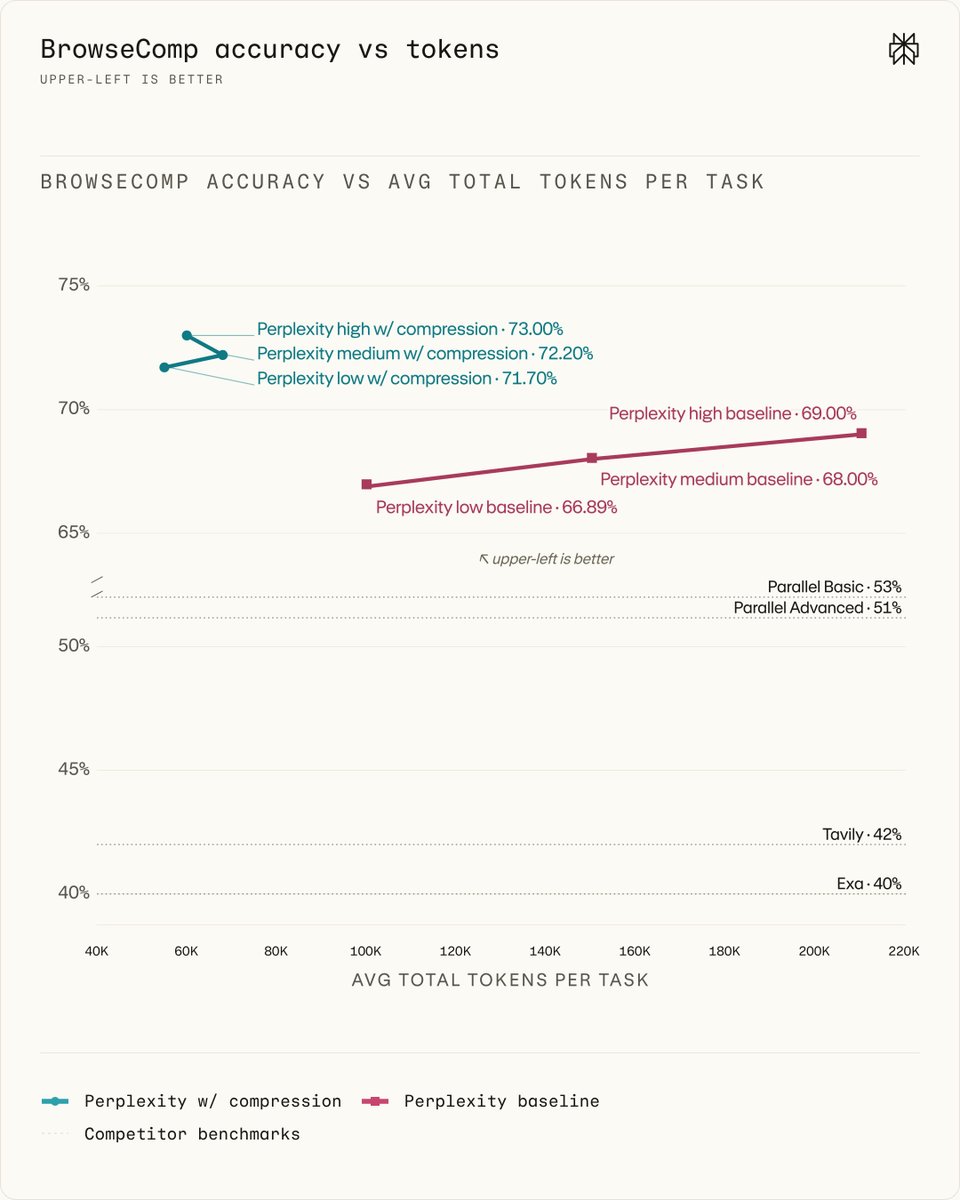
Perplexity open-sourced a rebuilt Unigram tokenizer that reduces CPU utilization by five to six times compared to standard implementations. While GPU inference often gets the focus, this update targets the hidden bottleneck of CPU-side tokenization for fast models like rerankers.
Perplexity, an AI-powered answer engine, open-sourced a rebuilt Unigram tokenizer that reduces CPU utilization by up to six times. The implementation targets the XLM-RoBERTa vocabulary and achieves zero heap allocations during the encoding process, eliminating a common source of processing stalls.
- CPU utilization reduction
- 5-6x
- Latency (514 tokens)
- 63 µs
- Speed vs Hugging Face
- 5x faster
- Speed vs SentencePiece (C++)
- 2x faster
- Memory allocation
- Zero heap allocations
This optimization addresses a growing bottleneck in retrieval-augmented generation (RAG) pipelines. While GPU compute for small rerankers is fast, CPU-side tokenization often accounts for a significant share of total latency. The release follows the launch of Perplexity's ROSE GPU inference engine to maximize hardware efficiency across the stack.
You can access the source code in the pplx-garden GitHub repository. The engine is written in Rust and outperforms the Hugging Face tokenizers crate by five times. It is designed for production environments where shaving double-digit milliseconds off reranker latency provides a measurable competitive advantage.