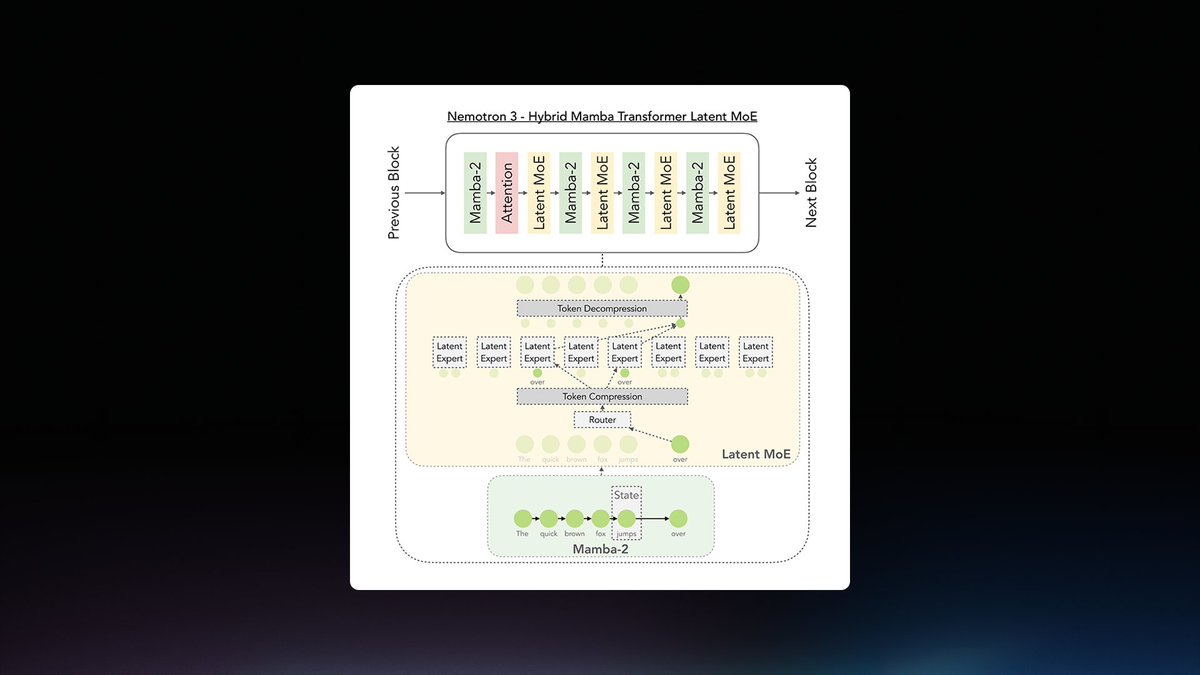
NVIDIA released Nemotron-Labs-Diffusion, a family of open-weight models that unify standard autoregressive decoding with parallel diffusion-based generation. By switching attention patterns within a single model, these 3B to 14B parameter models achieve up to 4x higher throughput on modern hardware compared to traditional sequential generation.
NVIDIA released Nemotron-Labs-Diffusion, a family of "tri-mode" models that unify standard autoregressive, diffusion, and self-speculation decoding. These 3B to 14B parameter models generate multiple tokens simultaneously by adjusting their attention pattern during inference, which is the process of running a model.
- Model scales
- 3B, 8B, and 14B parameters
- Decoding modes
- Autoregressive, Diffusion, and Self-Speculation
- Throughput gain
- 4x higher on NVIDIA GB200
- Tokens per forward pass
- 6x vs Qwen3-8B
- Variants
- Base, Instruct, and Vision-Language
- License
- NVIDIA Open Model License
Standard models are memory-bound, limited by the speed of moving weights for every token. This release shifts generation toward a compute-bound regime, better utilizing GPUs like the Blackwell architecture. By using diffusion to draft tokens and autoregressive logic to verify them, NVIDIA achieves higher acceptance lengths than existing multi-token prediction methods.
Base, instruct, and vision-language variants are available on Hugging Face under the NVIDIA Open Model License. They are compatible with the SGLang server and NVIDIA Dynamo. For developers building agents, these models maintain the accuracy of Nemotron 3 Super while delivering nearly 6x more tokens per forward pass.