Google DeepMind
@GoogleDeepMind
Gemini 3.1 Flash-Lite has landed. It’s our most cost-efficient Gemini 3 series model yet, built for intelligence at scale. Here’s what’s new 🧵
878retweets
View on X· Updated
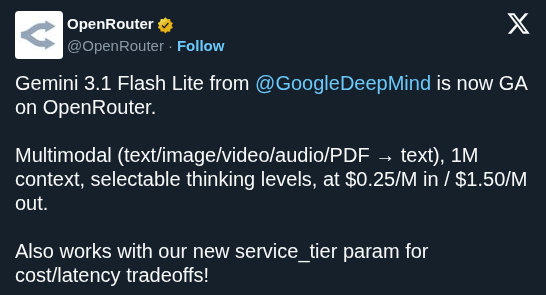
Google DeepMind released Gemini 3.1 Flash-Lite, its fastest and most cost-efficient Gemini 3 series model, priced at $0.25/1M input tokens. It outperforms 2.5 Flash with 2.5X faster response times, making high-volume AI tasks significantly cheaper and quicker to run.
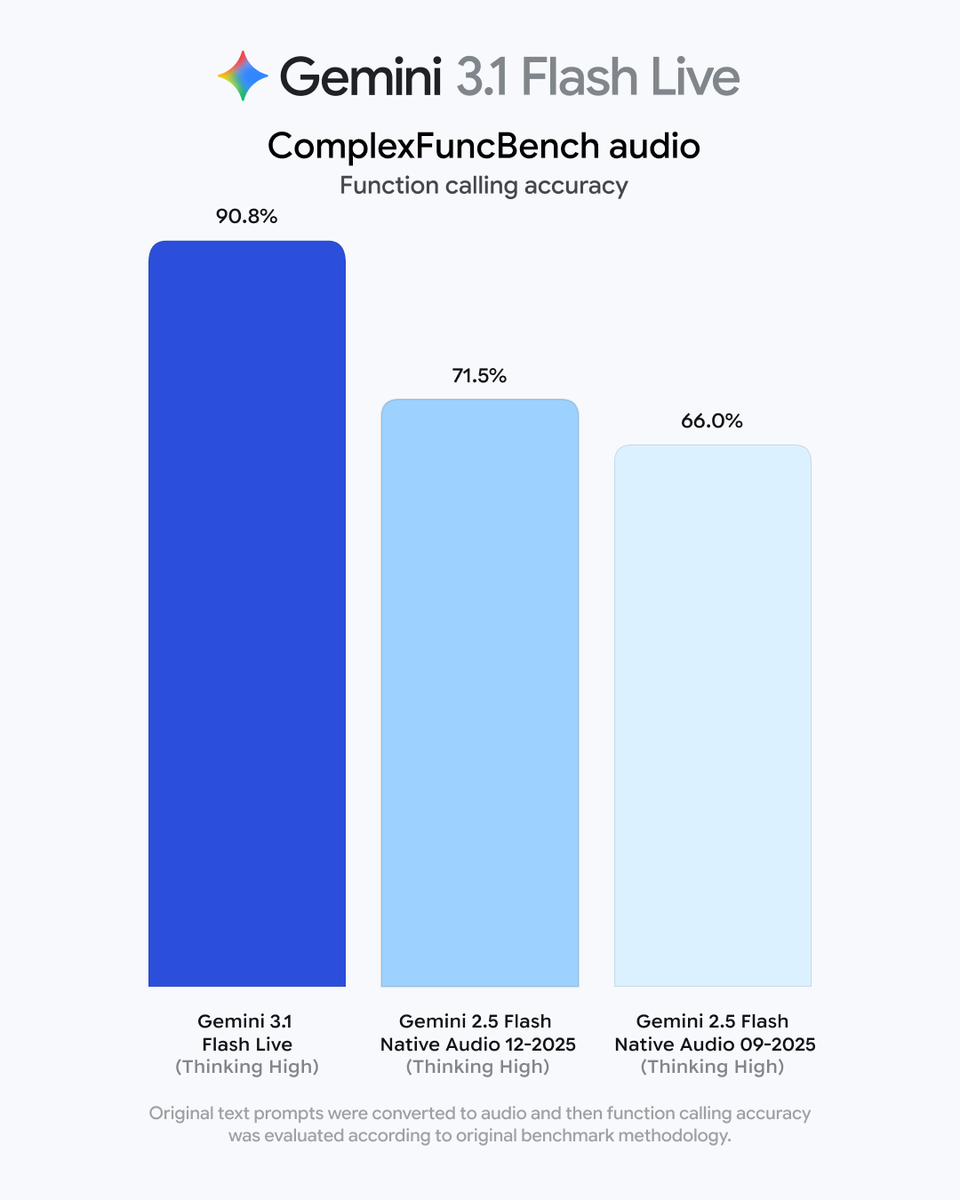
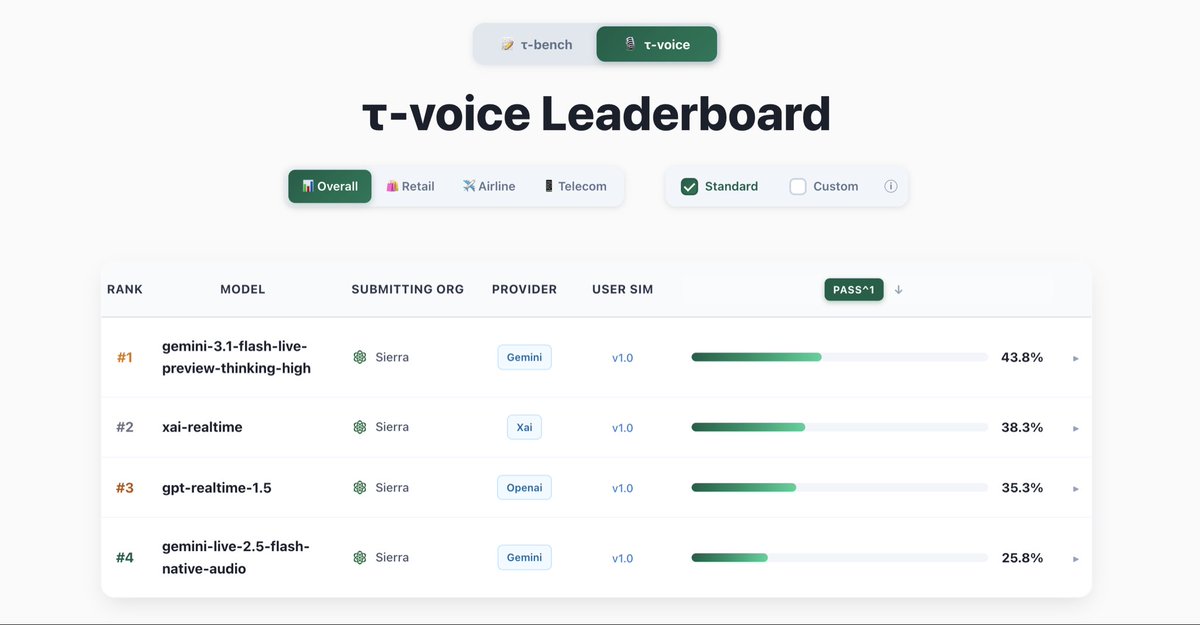
gemini-2.5-flash, per Artificial Analysis, an independent AI benchmarking and analysis company. It scores 86.9% on GPQA Diamond and 76.8% on MMMU Pro, outperforming larger prior-generation Gemini models. A new "thinking levels" feature lets developers dial in how deeply the model reasons — from high-volume translation and content moderation to UI generation and multi-step simulations.This brings affordable, fast reasoning to developer teams running inference at scale. The performance-per-dollar improvement gives product teams a credible option for latency-sensitive pipelines without the cost of larger models.
Build via the Gemini API in Google AI Studio using gemini-3.1-flash-lite-preview, or through Vertex AI for enterprise deployments. Use thinking levels to tune cost and reasoning depth per workload.
Gemini 3.1 Flash-Lite has landed. It’s our most cost-efficient Gemini 3 series model yet, built for intelligence at scale. Here’s what’s new 🧵
Every HeadsUpAI update is written based on its original source and reviewed before it's published. Read our editorial standards →
More like this