OpenRouter
@OpenRouter
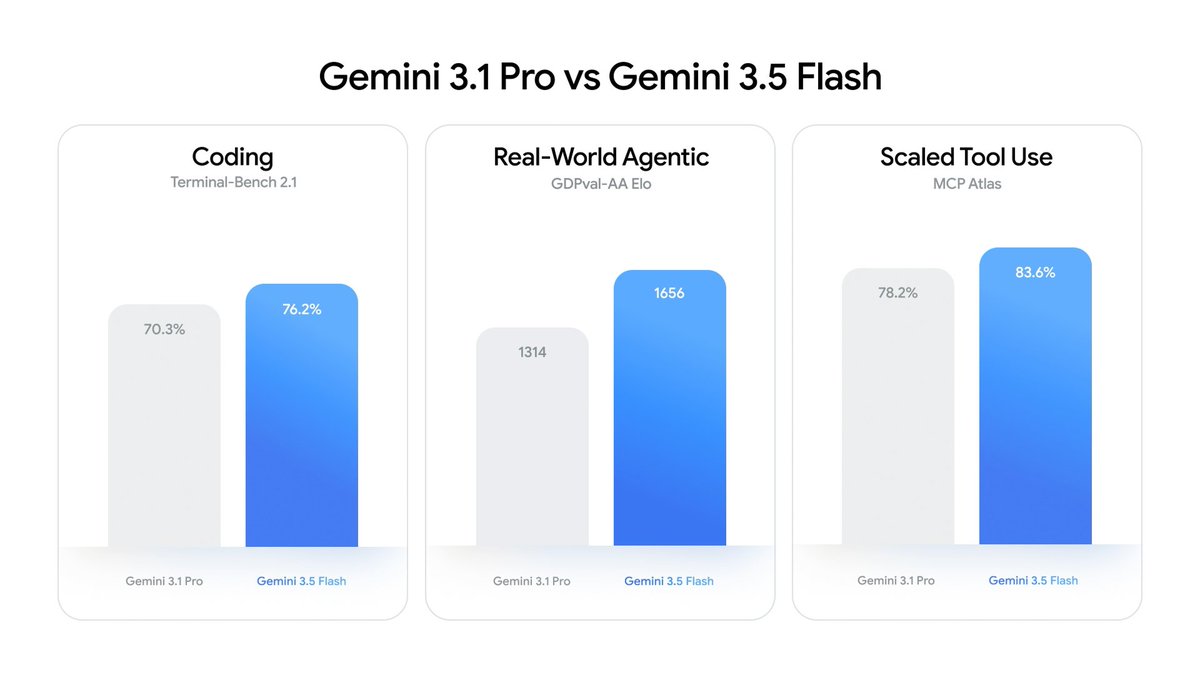
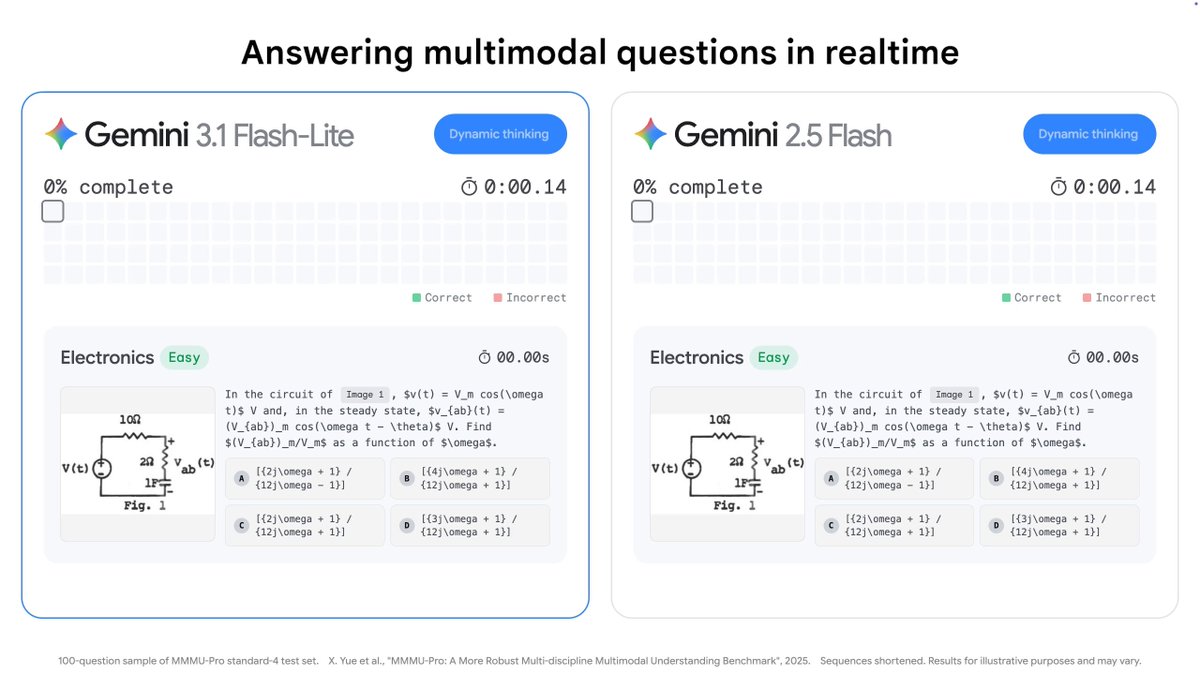
Gemini 3.1 Flash Lite from @GoogleDeepMind is now GA on OpenRouter. Multimodal (text/image/video/audio/PDF → text), 1M context, selectable thinking levels, at $0.25/M in / $1.50/M out. Also works with our new service_tier param for cost/latency tradeoffs!
12retweets351likes
View on X