Google moved Gemini 3.5 Flash to general availability, positioning it as the strongest agentic and coding model in the Gemini family. The release delivers frontier-level performance at 4x the speed of comparable competitor models, though pricing has risen 3x versus the previous Gemini 3 Flash.
Google launched Gemini 3.5 Flash globally as the strongest agentic and coding model in the Gemini family. The release delivers frontier-level performance at 4x the speed of comparable competitor models. The gemini-3.5-flash model ID supports a 1M token context window and 65K output tokens.
- Speed
- 4x comparable competitor models
- Pricing
- $1.50 input / $9.00 output per 1M tokens (3x previous Gemini 3 Flash)
- Model ID
- gemini-3.5-flash (1M context, 65K output)
- Benchmark
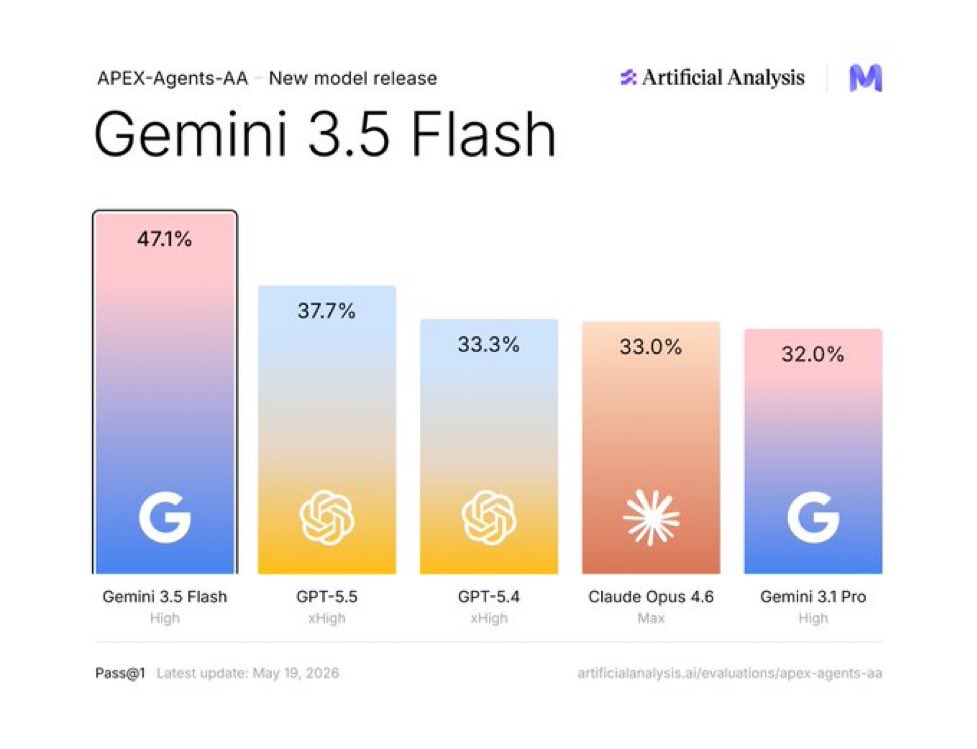
- Outperforms Gemini 3.1 Pro on coding and agentic tasks
- Next release
- Gemini 3.5 Pro shipping next month
The model outperforms the previous Gemini 3.1 Pro on coding and agentic benchmarks, shifting Pro-tier reasoning into Flash-series latency. A new thinking_level parameter (minimal/low/medium/high) replaces sampling controls, while thought preservation carries reasoning across multi-turn conversations.
Access it via the Gemini app, AI Mode in Google Search, Gemini API, Google Antigravity, Android Studio, and Gemini Enterprise Agent Platform. Standard tier pricing is $1.50 input and $9.00 output per million tokens — approximately 3x the cost of the previous Gemini 3 Flash. Gemini 3.5 Pro ships next month — matching GitHub Copilot's integration and OpenRouter's rollout.