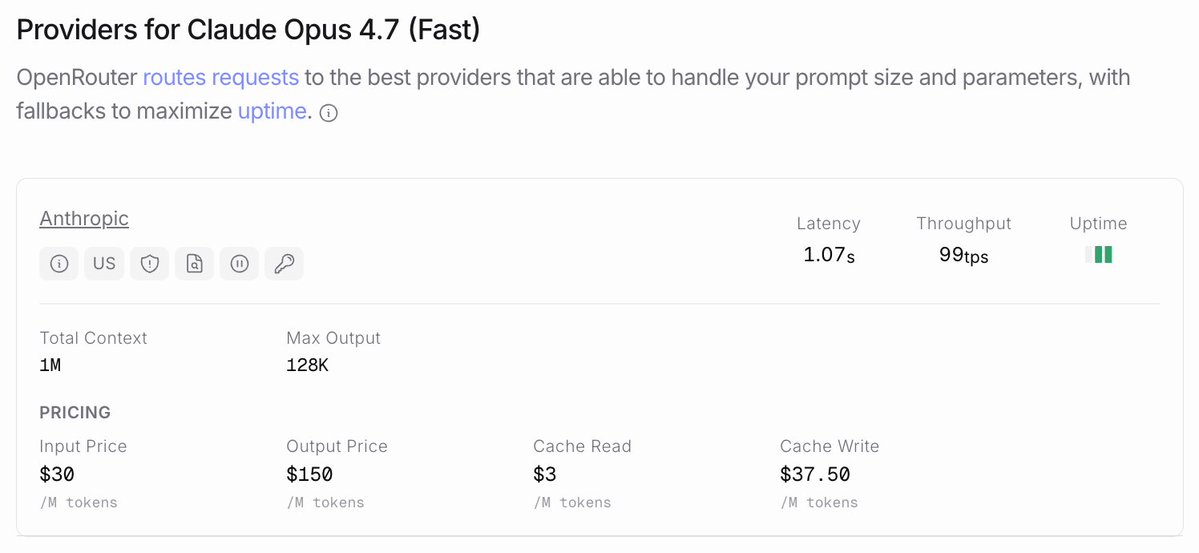
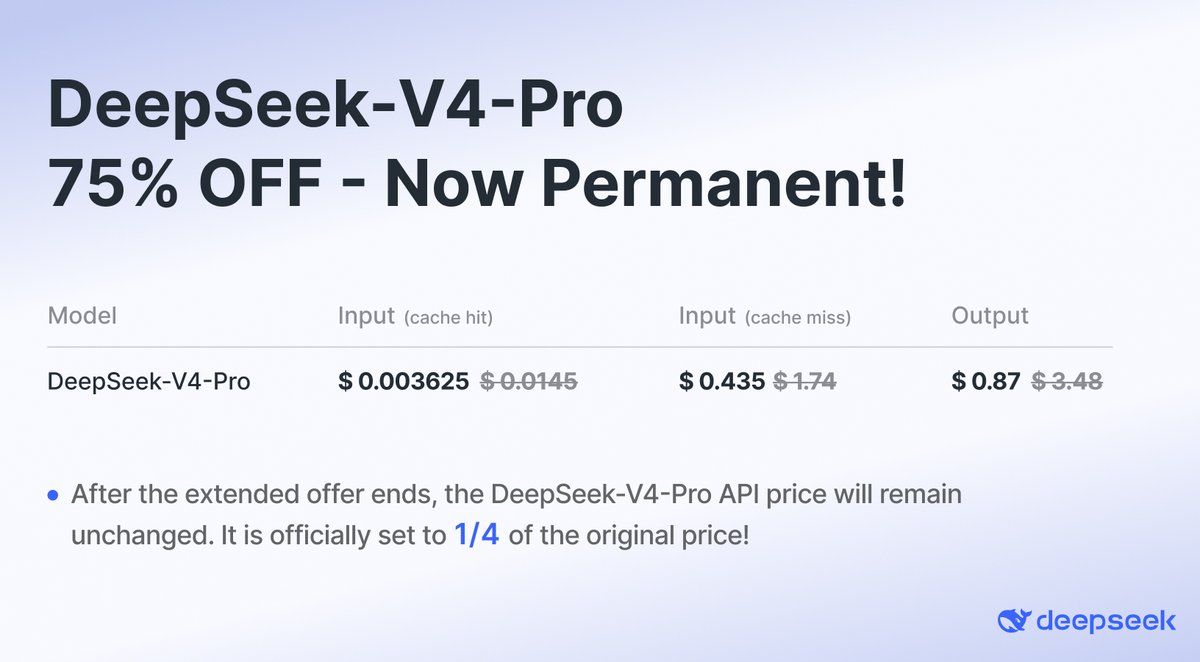
OpenRouter
@OpenRouter
⚡ New provider drop: AI-Native Cloud from @digitalocean is now live on OpenRouter. High performance inference across popular open-weight models. #1 on output speed and latency for DeepSeek V3.2 by @ArtificialAnlys. See their stats and try the models: https://t.co/baNXyerJzI https://t.co/Sg91fRVrsV
5retweets67likes
View on X