OpenRouter
@OpenRouter
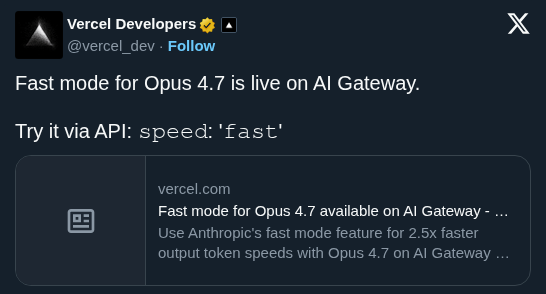
Opus 4.7 fast mode is live on OpenRouter! Just set your model to `anthropic/claude-opus-4.7-fast` Full Opus 4.7 intelligence with ~2.5x faster throughput https://t.co/EzYmE7HuA5
8retweets182likes
View on X· Updated
OpenRouter enabled a high-speed inference tier for Anthropic's flagship model, delivering 2.5x faster throughput at a 6x price premium. This update allows developers to trade capital for speed in latency-sensitive agentic workflows without sacrificing reasoning depth.
Latency is the primary bottleneck for autonomous workflows requiring sequential reasoning steps. While Opus 4.7's tokenizer previously impacted costs, this update introduces a deliberate trade-off between speed and capital. It mirrors the industry shift toward specialized inference tiers where performance is optimized for high-volume production agents.
Access the tier via the anthropic/claude-opus-4.7-fast model ID. It is priced at a 6x premium of $30 per million input tokens and $150 per million output tokens. This is effective for asynchronous agent pipelines where task completion speed is more valuable than per-token cost efficiency.
Opus 4.7 fast mode is live on OpenRouter! Just set your model to `anthropic/claude-opus-4.7-fast` Full Opus 4.7 intelligence with ~2.5x faster throughput https://t.co/EzYmE7HuA5
Still wondering? A few quick answers below.
Every HeadsUpAI update is written based on its original source and reviewed before it's published. Read our editorial standards →
More like this