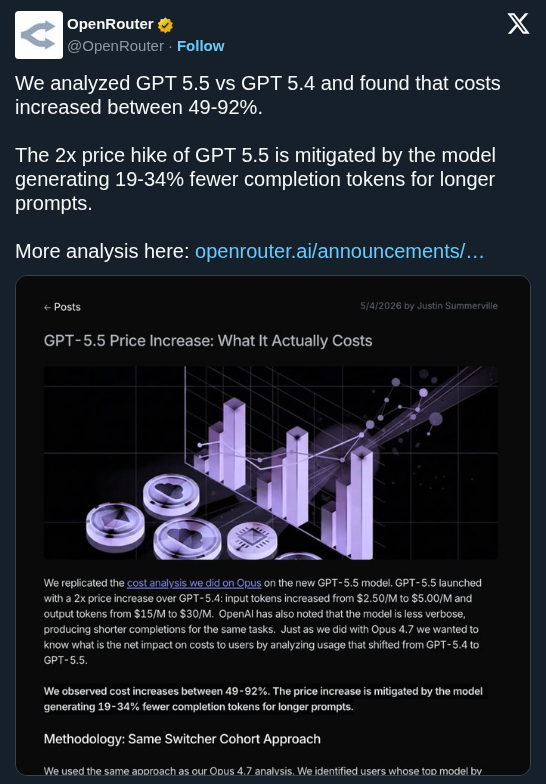
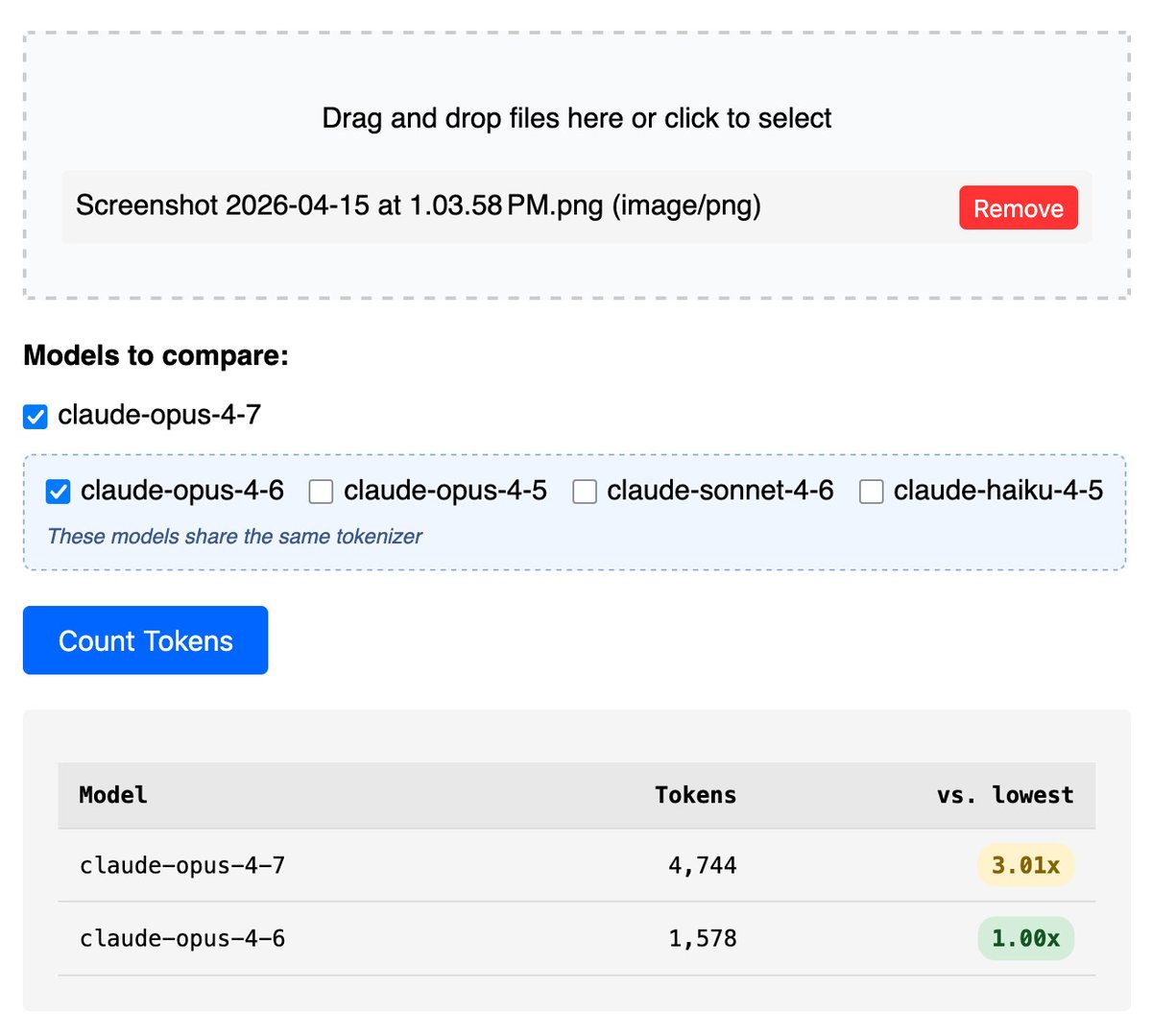
OpenRouter's study of Opus 4.7 reveals that changes to the model's tokenizer have increased actual costs by 12% to 27% for most users. While short prompts have become more efficient, the shift highlights how token density can drive up expenses even when per-token pricing remains stable.
OpenRouter studied market data for the new Opus 4.7 and found that real-world costs increased by 12% to 27% for most users. This shift is driven by the model's tokenizer—the system that converts text into numerical tokens (the basic units of text processing). Short prompts were the only exception, showing improved efficiency.
This finding highlights a hidden variable in AI economics: token density. If a provider maintains the same price per million tokens, a less efficient tokenizer requires more tokens to represent the same sentence, effectively raising the price. This trend mirrors GitHub Copilot's usage-based billing as providers manage rising compute demands.
You should re-evaluate your API budget if your workflows rely on long-context prompts, as these now carry a significant cost increase. Conversely, applications using very short prompts may see slight cost improvements. These findings are based on OpenRouter's analysis and apply to their unified API.