Vercel Developers
@vercel_dev
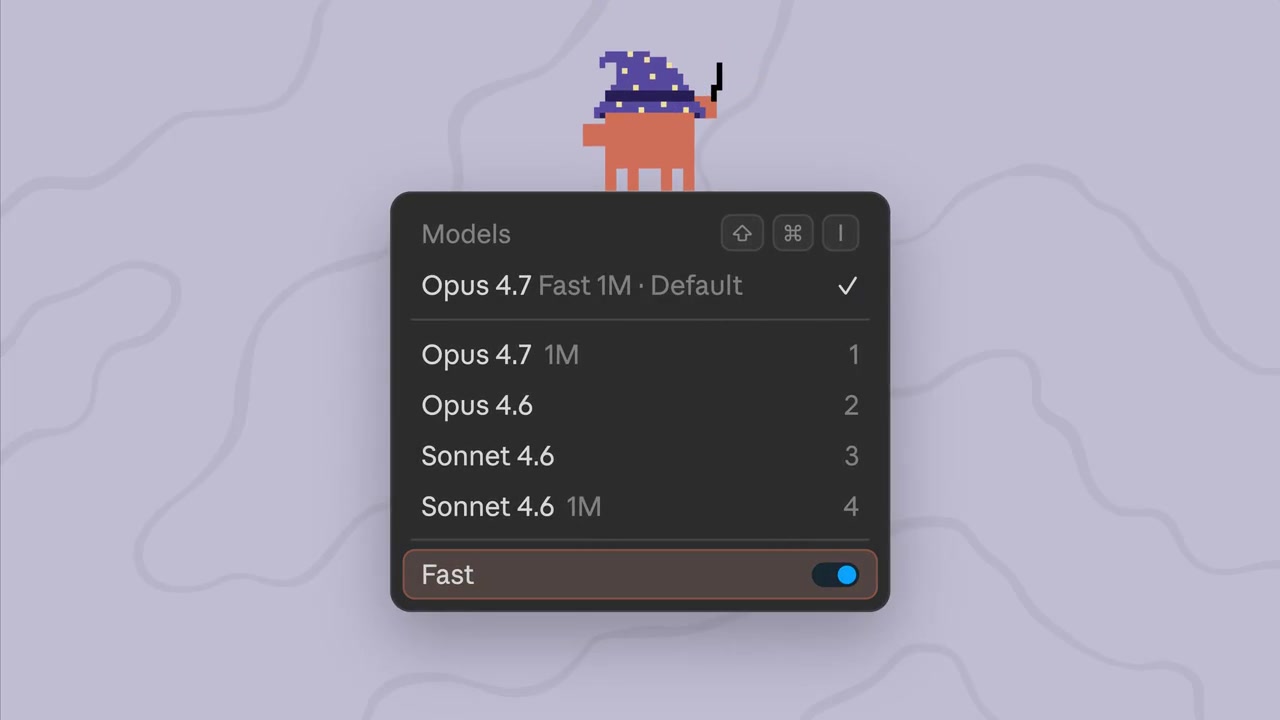
Fast mode for Opus 4.7 is live on AI Gateway. Try it via API: 𝚜𝚙𝚎𝚎𝚍: '𝚏𝚊𝚜𝚝' https://t.co/i8v3oiLPph
38likes
View on X· Updated
Vercel added a high-speed inference tier for Anthropic's Claude Opus 4.7 on its AI Gateway, delivering 2.5x faster output token generation. This update allows developers to trade higher costs for reduced latency in complex agentic loops where reasoning speed is the primary bottleneck.
This update mirrors OpenRouter's high-speed inference tier by addressing the latency bottleneck in high-reasoning models. While Opus 4.7 provides deep intelligence, its standard speed can disrupt autonomous tasks. By offering a speed-for-spend tradeoff, Vercel ensures its infrastructure remains competitive for Windsurf's Opus 4.7 integration.
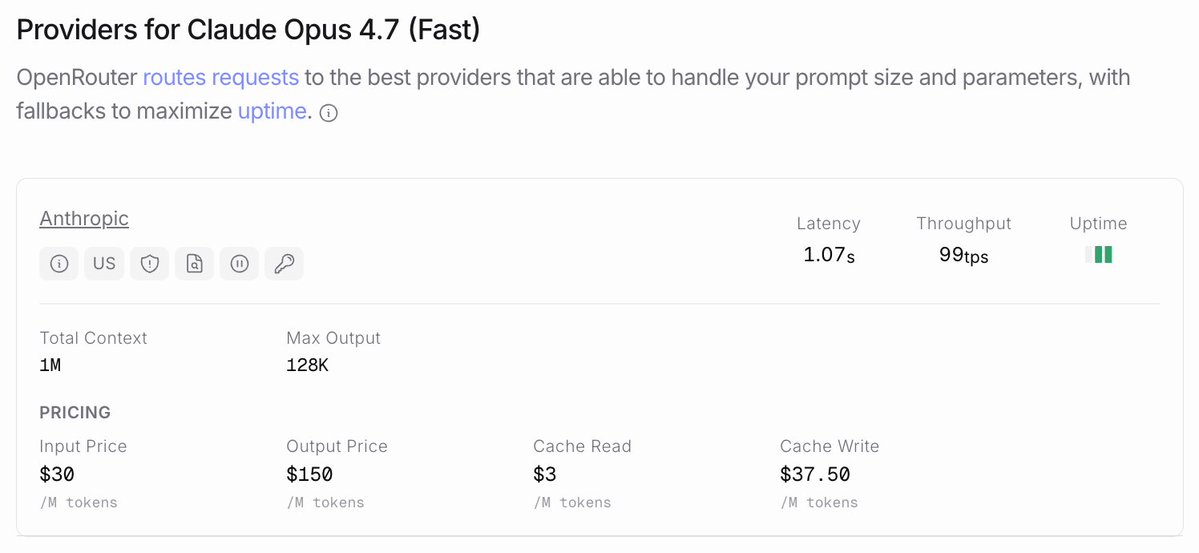
To enable the feature, pass the speed: 'fast' parameter within the anthropic provider options of the AI SDK. It is also compatible with Claude Code via environment variables. The release follows Vercel's AI Gateway production index report. Fast mode is priced at a 6x premium, costing $30 per million input tokens and $150 per million output tokens.
Fast mode for Opus 4.7 is live on AI Gateway. Try it via API: 𝚜𝚙𝚎𝚎𝚍: '𝚏𝚊𝚜𝚝' https://t.co/i8v3oiLPph
Still wondering? A few quick answers below.
Every HeadsUpAI update is written based on its original source and reviewed before it's published. Read our editorial standards →
More like this