OpenRouter
@OpenRouter
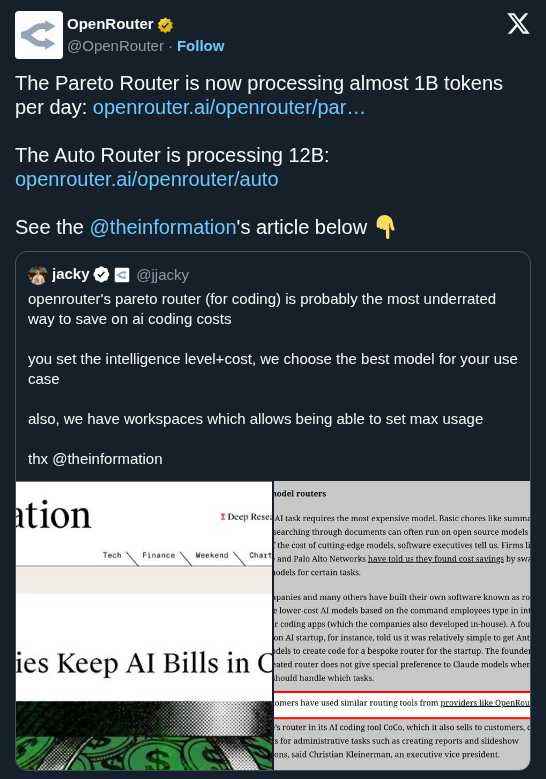
Don't rely on benchmarks; look at the full picture! Try our new Compare page, which also lets you visualize model performance: https://t.co/lc6teV2Tpz https://t.co/onsVfvu7vs
9retweets133likes
View on X· Updated
OpenRouter released a new comparison interface that visualizes live performance metrics, pricing, and token usage trends across hundreds of LLMs. By moving beyond static benchmarks, the tool helps developers select models based on actual production data like p50 latency and reasoning token volume.
p50 latency (the time it takes for half of requests to complete) and throughput alongside granular pricing for input, output, and cached tokens.As reasoning models become standard, static benchmarks no longer capture the full operational picture. This update provides transparency into production behavior, including 30-day usage trends that distinguish between prompt, completion, and reasoning tokens (tokens generated during internal deliberation). It follows OpenRouter's Pareto Code launch.
You can compare specific model variants, such as adaptive reasoning modes, across multiple providers. The Design Arena section also offers specialized rankings for tasks like SVG generation, which complements OpenRouter's Recraft V4.1 integration for vector graphics. The comparison tool is available for free on the OpenRouter website.
Don't rely on benchmarks; look at the full picture! Try our new Compare page, which also lets you visualize model performance: https://t.co/lc6teV2Tpz https://t.co/onsVfvu7vs
Still wondering? A few quick answers below.
Every HeadsUpAI update is written based on its original source and reviewed before it's published. Read our editorial standards →
More like this