OpenRouter
@OpenRouter
The Pareto Router is now processing almost 1B tokens per day: https://t.co/IHsAo9CuqH The Auto Router is processing 12B: https://t.co/MewkWfiOm0 See the @theinformation's article below 👇
5retweets54likes
View on X· Updated
OpenRouter's automated routing engines now process 13 billion tokens daily, with the coding-specific Pareto Router hitting 1 billion. The milestone coincides with new granular controls that let users manually balance model performance against token costs. This shift highlights how developers are moving from static model selection to dynamic, algorithmic orchestration to manage AI expenses.
DeepSeek V4 Pro.This surge follows a $113M funding round and reflects a shift toward multi-model production. By using a meta-model to manage inference (running a trained model to generate outputs), developers hedge against downtime and capture price drops. This layer commoditizes individual models in favor of consistent performance and cost efficiency.
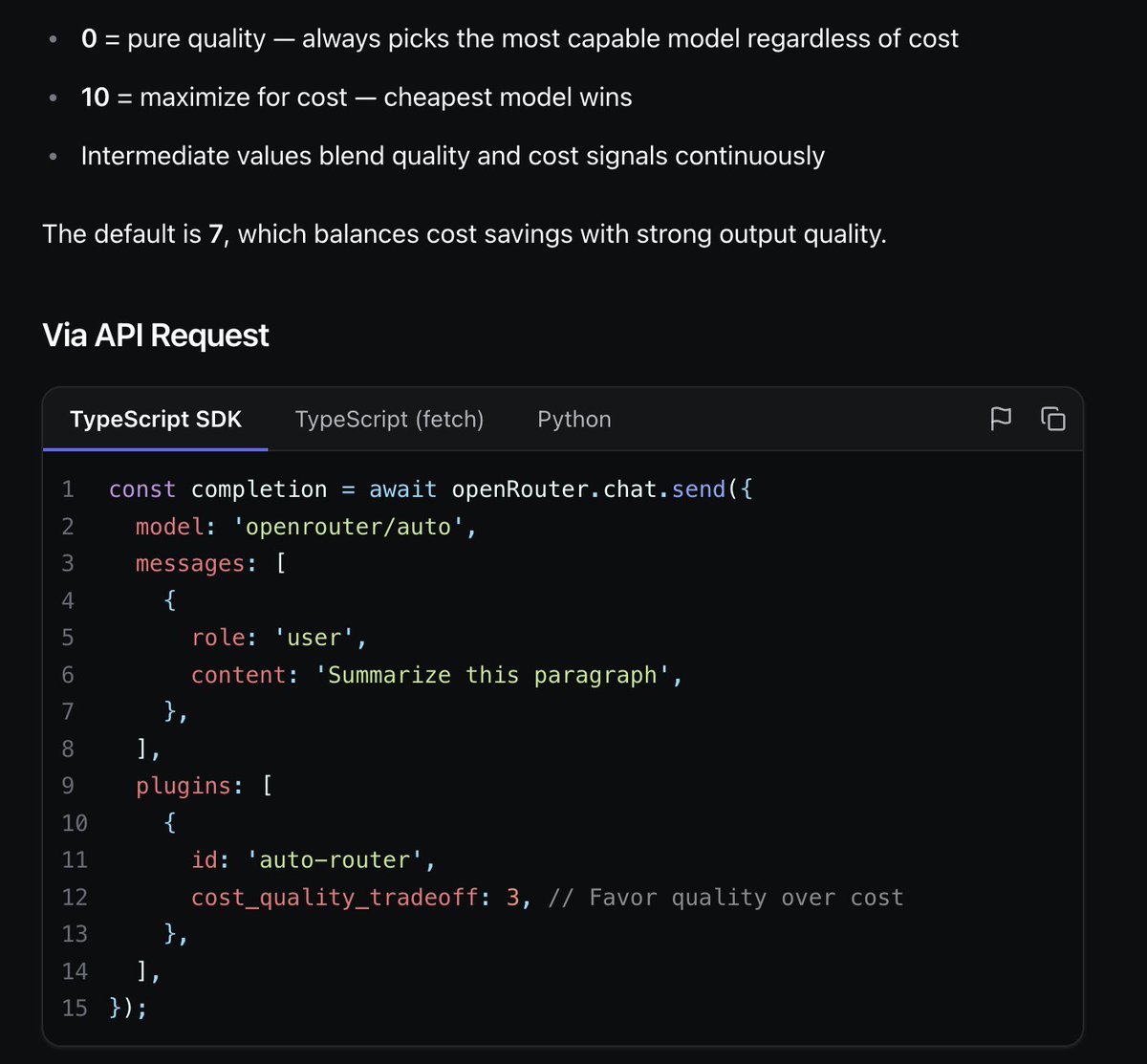
Both routers are customizable through OpenRouter's Guardrails and usage limits in the routing dashboard, letting teams cap spend and steer selection. OpenRouter also offers a cost-quality slider for balancing model intelligence against token cost across routine and reasoning-heavy tasks.
The Pareto Router is now processing almost 1B tokens per day: https://t.co/IHsAo9CuqH The Auto Router is processing 12B: https://t.co/MewkWfiOm0 See the @theinformation's article below 👇
Still wondering? A few quick answers below.
Every HeadsUpAI update is written based on its original source and reviewed before it's published. Read our editorial standards →
More like this