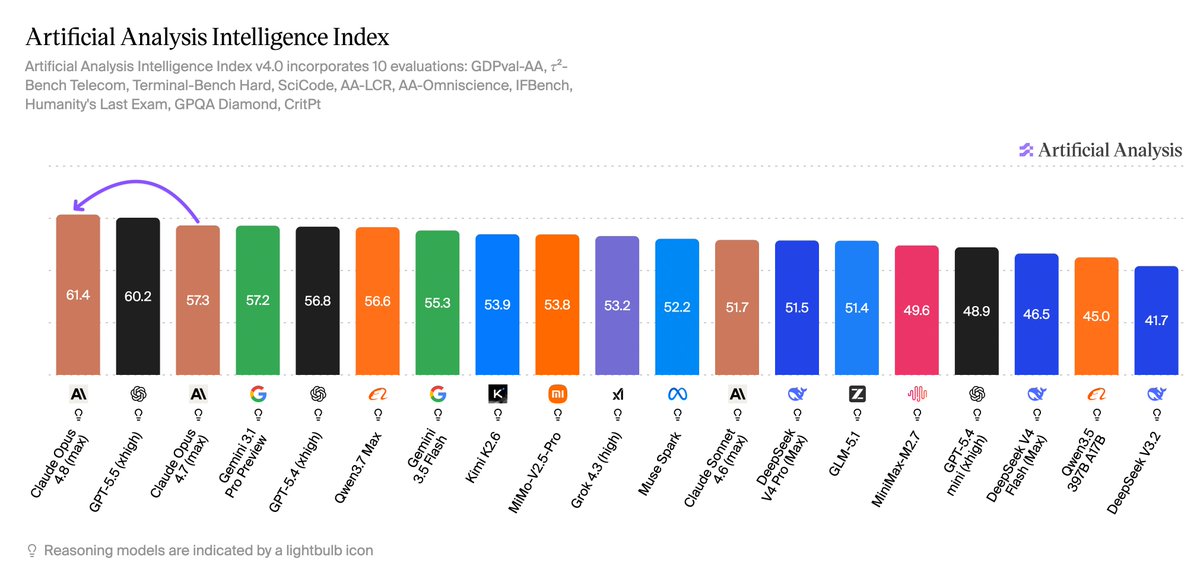
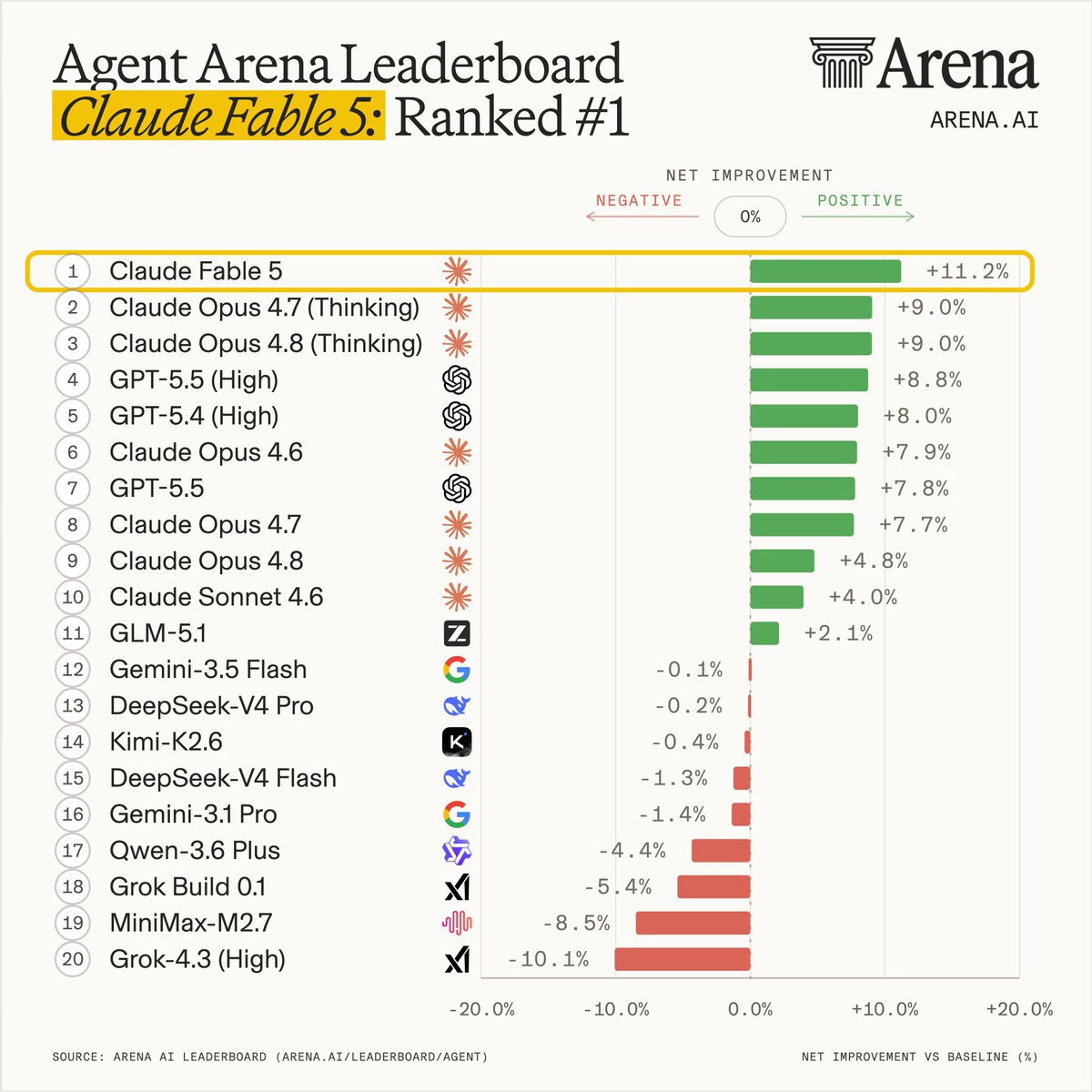
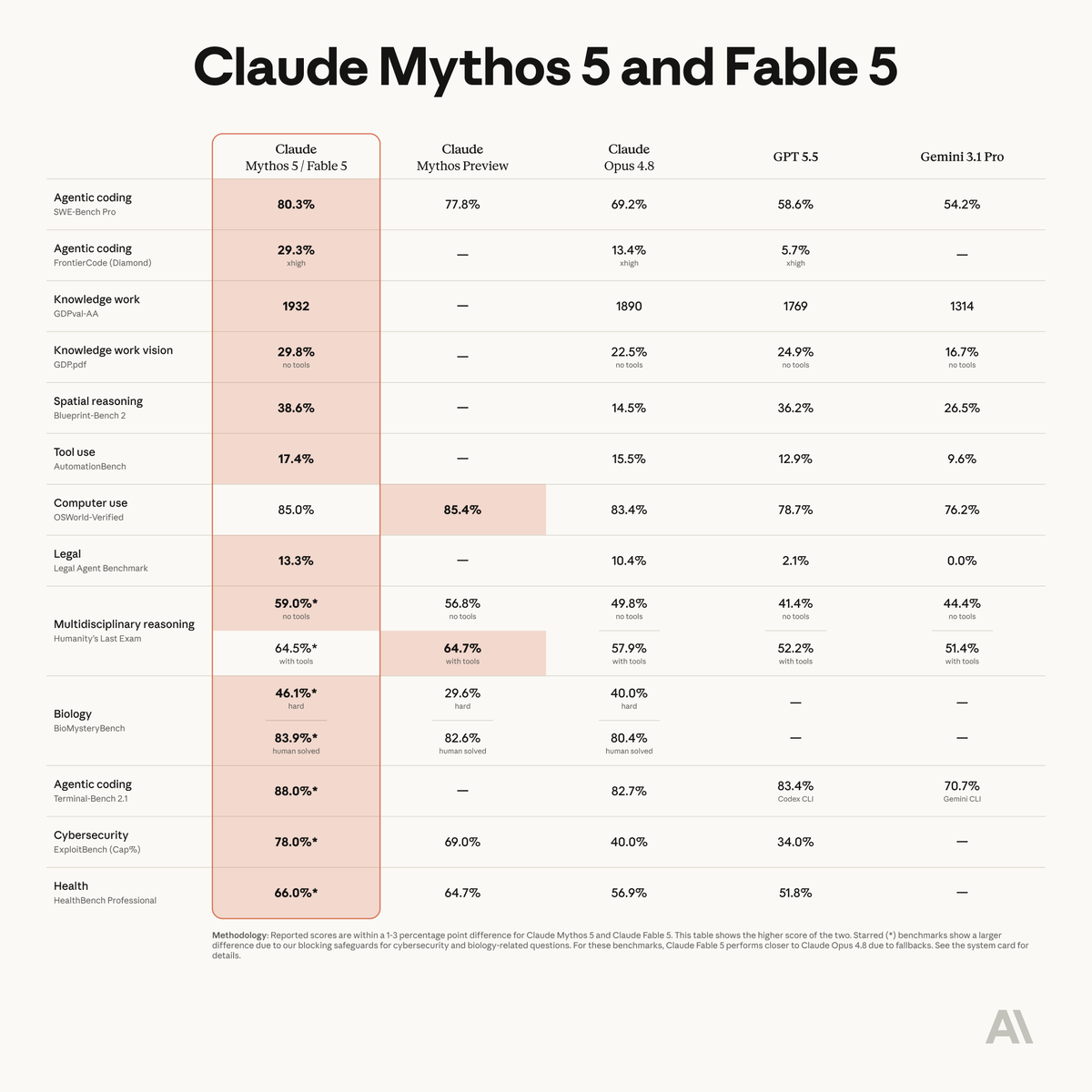
Claude Fable 5 launched today at #1 on the Artificial Analysis Intelligence Index, putting Anthropic nearly 5 points ahead of any other lab’s best model We supported @AnthropicAI with pre-release evaluation of Claude Fable 5. Claude Fable 5 scores 64.9 on the Artificial Analysis Intelligence Index, claiming the #1 rank overall. It is ~5 points ahead of the closest non-Anthropic model (GPT-5.5), and Anthropic models now occupy both of the top 2 places. Key takeaways for Claude Fable 5 (adaptive reasoning with max effort and Opus 4.8 as fallback model): ➤ New safety guardrails for Mythos-class models: Claude Fable 5 uses the same underlying model as Claude Mythos 5 for public usage, with additional guardrails for potentially-harmful cybersecurity, biology, chemistry, and distillation-related queries. We tested Fable 5 using Anthropic’s new ‘fallback’ mechanism, which can route safety-flagged messages to Claude Opus 4.8. Anthropic states that fallback occurs in fewer than 5% of sessions on average, and we recorded fallback routing in ~8% of tasks across the Intelligence Index (mostly in scientific questions from evaluations like GPQA, AA-Omniscience and Humanity’s Last Exam) ➤ State-of-the-art Intelligence: Claude Fable 5 takes the #1 position on the Artificial Analysis Intelligence Index, scoring 64.9 and setting the highest score on 5 of the 10 underlying benchmarks. On AA-Omniscience, our knowledge and hallucination benchmark, Fable 5 scores 40, +7 points over the previous leader, Gemini 3.1 Pro Preview, driven primarily by higher accuracy. We generally observe a strong relationship between AA-Omniscience accuracy and model size in open weights models, which suggests Fable 5 could be larger than previous public Anthropic models ➤ Frontier agentic capability: Claude Fable 5 is at the frontier across all three agentic evaluations in the Index: GDPval-AA (real-world work tasks), Terminal-Bench Hard (agentic coding), and Tau2-bench Telecom (tool use for customer service). Its GDPval-AA Elo of 1932 is a significant jump from the previous leader, Claude Opus 4.8, further extending Anthropic’s lead in agentic capabilities ➤ Leading HLE score, but refusal and fallback in 9% of tasks: Claude Fable 5 scores 53% on Humanity’s Last Exam, more than 7 points ahead of the next-best model, Claude Opus 4.8 (max). Fable 5 triggers safety guardrails on 9% of HLE tasks, falling back to Claude Opus 4.8. Including this fallback usage, running HLE with Fable 5 costs ~$2.2k, the highest of any model we have evaluated Key model details: ➤ Context window: Claude Fable 5 retains the same 1M token context window as Claude Opus 4.8 ➤ Price: Claude Fable 5 is priced at $10/$50 per 1M input/output tokens, 2x the token price of Claude Opus 4.8. The cache write/read price is $12.50/$1 per million tokens ➤ Availability: Claude Fable 5 is included in Pro, Max, Team, and seat-based Enterprise plans through June 22, consuming 2x Opus usage. From June 23, usage will require credits, with Anthropic saying it plans to restore subscription access once capacity allows
Artificial Analysis Ranks Claude Fable 5 #1 on Intelligence Index
Artificial Analysis ranks Anthropic’s Claude Fable 5 first on its Intelligence Index with a score of 64.9, leading the next-best model by nearly 5 points. The model introduces safety guardrails that route flagged queries to Claude Opus 4.8 and achieves frontier performance across agentic benchmarks, including GDPval-AA and Terminal-Bench Hard.
Artificial Analysis
@ArtificialAnlys
69retweets793likes
View on XEvery HeadsUpAI update is written based on its original source and reviewed before it's published. Read our editorial standards →