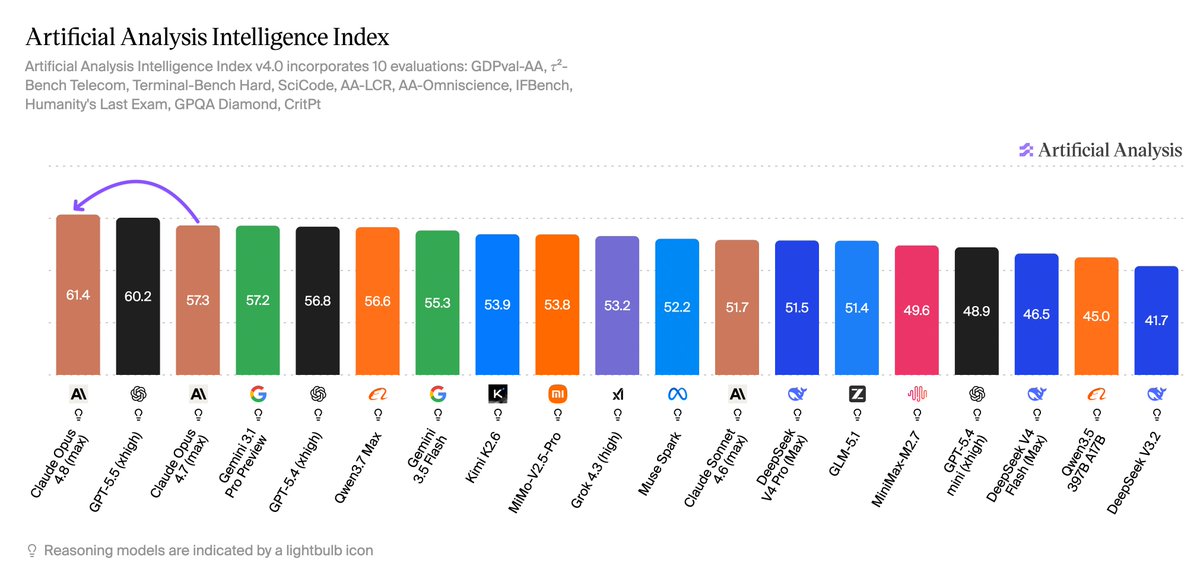
OpenBMB has released MiniCPM5-1B (Non-reasoning), the leading 1B open weights model, scoring 17.9 on the Artificial Analysis Intelligence Index @OpenBMB is a China-based lab jointly founded in 2022 by Tsinghua University’s NLP Lab and ModelBest Inc. This release extends the open weights Pareto frontier for Intelligence vs. Parameters at the sub-2B scale. It sits almost 2 points ahead of the best-performing 2B open weights model, @Alibaba's Qwen3.5 2B (Reasoning, 16.3), and 7 points ahead of Qwen3.5 0.8B (Reasoning, 10.5). Unlike the recently released MiniCPM-V 4.6 1.3B Instruct, MiniCPM5-1B (Non-reasoning) does not support native multimodal input, and is text input and output only. Key results: ➤ MiniCPM5-1B scores 17.9 on the Artificial Analysis Intelligence Index, the highest of any open weights model at 1B parameters or below by 7.4 points. The next-most-intelligent open weights model at this scale is Qwen3.5 0.8B (Reasoning, 10.5). No other open weights model under 2B parameters has exceeded 15 on the Intelligence Index; its predecessor MiniCPM-V 4.6 1.3B sits at 12.7. ➤ MiniCPM5-1B extends the open weights Pareto frontier on both Intelligence vs. Total Parameters and Intelligence vs. Active Parameters at the sub-2B scale. It surpasses its predecessor MiniCPM-V 4.6 1.3B (12.7) by 5.3 points at ~23% fewer parameters, and beats Qwen3.5 2B (Reasoning, 16.3) by 1.6 points at less than half the parameter count. ➤ MiniCPM5-1B is more token-efficient than the larger reasoning peers it surpasses, but uses more output tokens than its (also non-reasoning) predecessor MiniCPM-V 4.6 1.3B. It used 12.6M output tokens to run the Intelligence Index, ~31x fewer than Qwen3.5 2B (Reasoning, 389M) and ~8x fewer than Qwen3.5 2B (Non-reasoning, 100M), but ~2.3x more than MiniCPM-V 4.6 1.3B's 5.4M. ➤ AA-Omniscience score of -1 is the highest in its size class, earned by abstaining rather than hallucinating. MiniCPM5-1B declines to answer the vast majority of AA-Omniscience questions, avoiding the hallucination penalty that pulls sub-2B peers down to the -70 to -89 range (Qwen3.5 0.8B Non-reasoning at -89, MiniCPM-V 4.6 1.3B at -85, Exaone 4.0 1.2B Non-reasoning at -83). Choosing to abstain rather than guess is the more honest posture, and AA-Omniscience credits it positively. Additional model details: ➤ Size: 1B total parameters (dense) ➤ Context window: 128K ➤ Modality: Text input and output only ➤ Precision: BF16 ➤ License: Apache 2.0 ➤ Providers: No confirmed providers upon release
OpenBMB MiniCPM5-1B sets new intelligence record for sub-2B models
· Updated
OpenBMB released MiniCPM5-1B, which scored 17.9 on the Artificial Analysis Intelligence Index. The model outperforms larger 2B-parameter reasoning models while maintaining extreme token efficiency and a low hallucination rate.
- Intelligence Index Score
- 17.9
- AA-Omniscience Score
- -1
- Context Window
- 128K
- License
- Apache 2.0
- Parameter Count
- 1B (dense)
The model extends the Pareto frontier for small language models, beating the Qwen3.5 2B reasoning model by 1.6 points despite having half the parameters. This suggests that high-quality training can deliver frontier-level intelligence in compact architectures without the computational cost of extended thinking tokens. It used 12.6M output tokens to run the index, significantly less than its larger peers.
For those deploying on-device AI, this model offers extreme token efficiency, using 31x fewer output tokens than larger reasoning peers. It also features a high honesty rate, scoring -1 on the AA-Omniscience index by choosing to abstain from answering rather than hallucinating. The weights are available under an Apache 2.0 license for local implementation, though no API providers are confirmed at release.
Every HeadsUpAI update is written based on its original source and reviewed before it's published. Read our editorial standards →