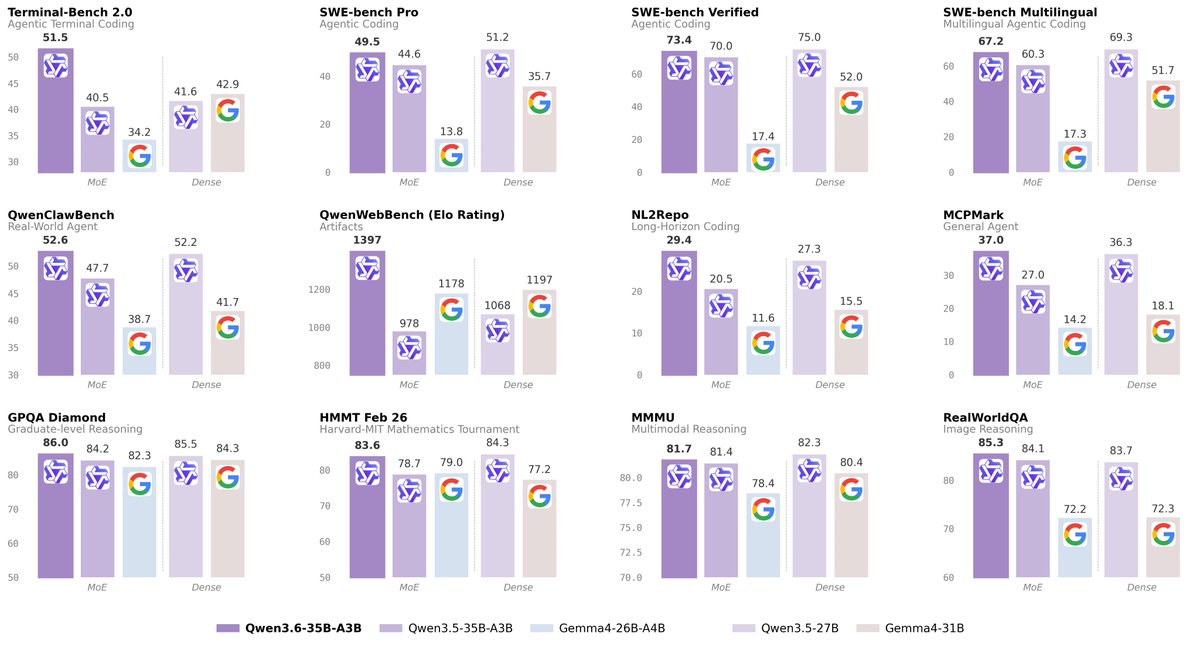
Alibaba's Qwen team released four medium-sized models that match their previous flagship while activating a fraction of the parameters. The standout Qwen3.5-35B-A3B uses just 3 billion active parameters yet surpasses Qwen3-235B-A22B across reasoning, coding, and agentic benchmarks.
Qwen released the Qwen 3.5 Medium Model Series - four models spanning Qwen3.5-Flash, Qwen3.5-35B-A3B, Qwen3.5-122B-A10B, and Qwen3.5-27B. The headline result is the 35B-A3B: a sparse mixture-of-experts model that activates just 3 billion parameters per forward pass, yet matches or exceeds the previous 235B flagship across SWE-bench Verified, GPQA Diamond, and agentic tool-use benchmarks.
The architecture combines Gated Delta Networks for linear attention with sparse MoE layers, delivering high throughput at a fraction of the inference cost. All models support native vision-language understanding through early fusion training and 201 languages out of the box. Qwen3.5-Flash, the hosted production version, extends context to 1 million tokens.
Weights for the open models are available on Hugging Face, compatible with vLLM, SGLang, and Transformers.