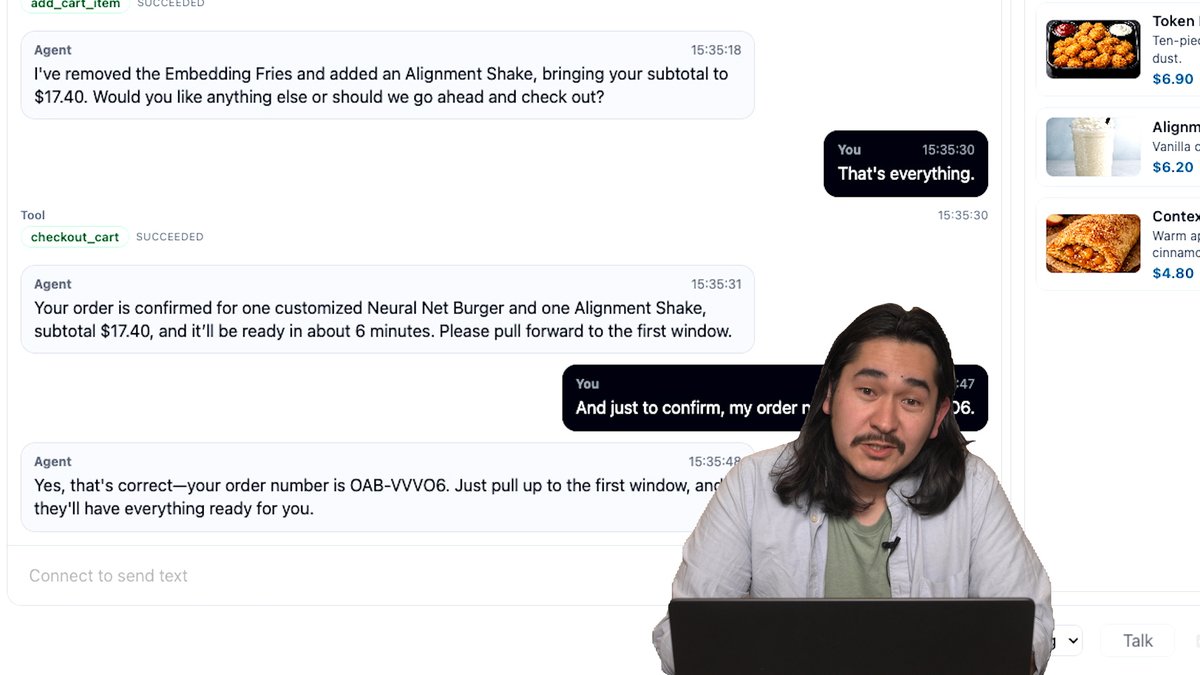
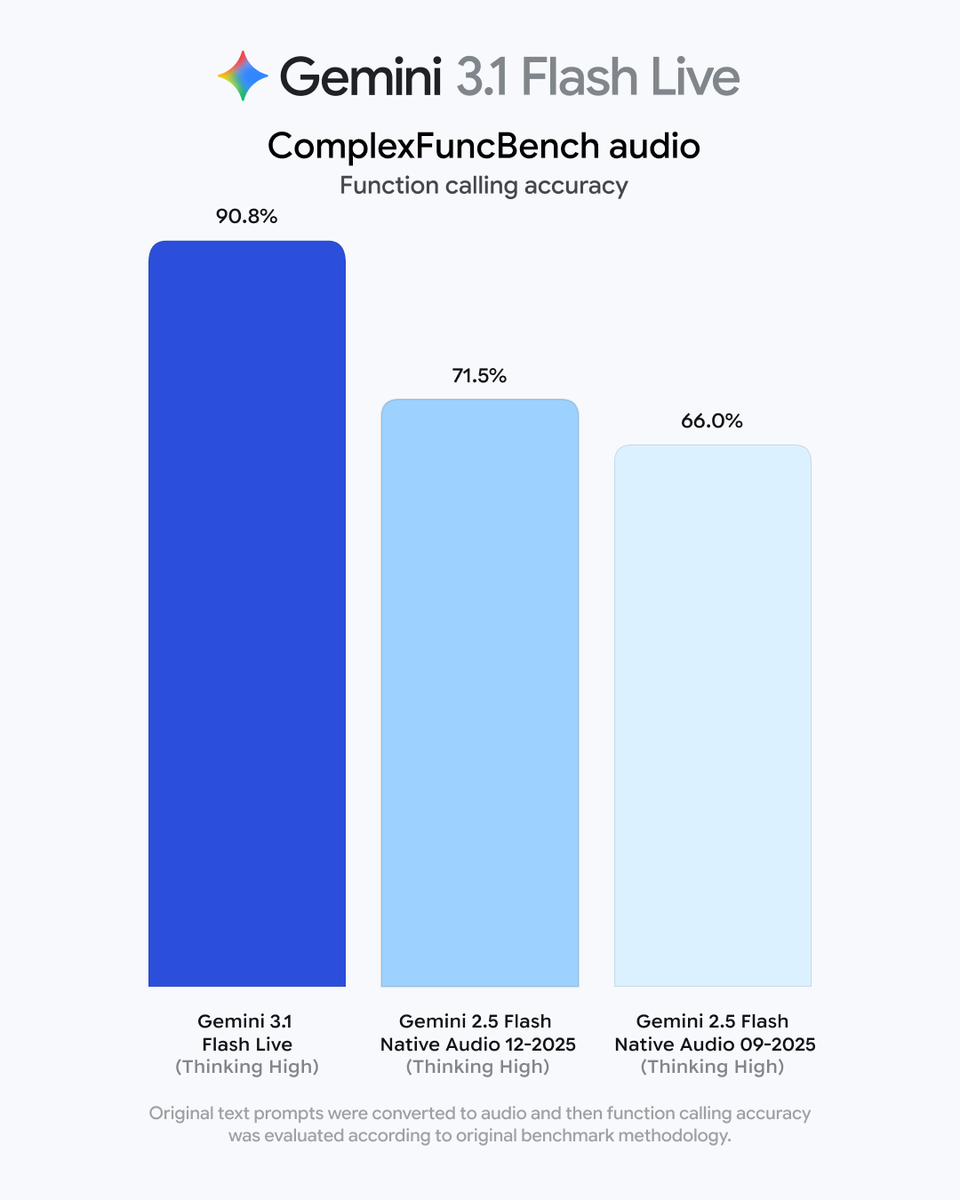
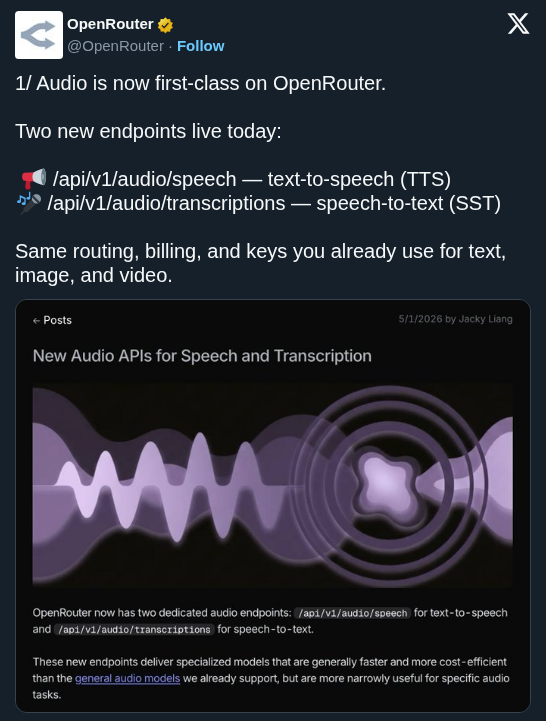
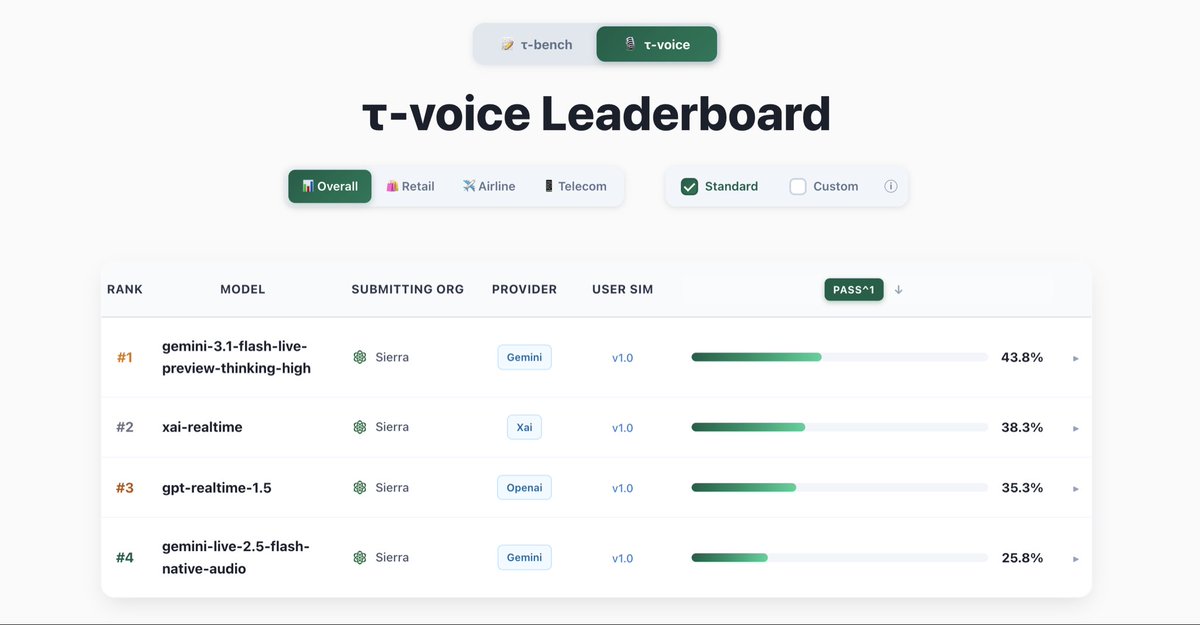
OpenAI released GPT-Realtime-2 alongside new streaming translation and transcription models in its Realtime API. This update shifts voice AI from simple conversational loops to reasoning-capable agents that can solve complex problems and handle interruptions in real time.
OpenAI released GPT-Realtime-2, a new audio-native model for its Realtime API that adds reasoning to voice interactions. The suite includes GPT-Realtime-Translate, supporting streaming translation across 70 languages, and GPT-Realtime-Whisper for live transcription. These models enable bidirectional, low-latency audio streams for production-ready voice agents.
- GPT-Realtime-2 capability
- GPT-5-class reasoning
- Translation support
- 70+ input and 13 output languages
- Transcription model
- GPT-Realtime-Whisper
- API parameter
- reasoning.effort
- Availability
- Realtime API
This release bridges the gap between the GPT-5.5 reasoning models and OpenAI's WebRTC infrastructure updates. By moving reasoning into the audio modality, voice agents can now handle natural conversational interruptions and solve multi-step problems as they unfold. This shifts the paradigm from reactive chatbots to collaborative agents capable of complex real-time logic.
You can access these models through the Realtime API to build voice-first applications like live interpreters or technical support agents. Developers can use the reasoning.effort parameter to balance intelligence with latency requirements. While these capabilities are live in the API, OpenAI noted that they are not yet available within the consumer ChatGPT application.