OpenRouter
@OpenRouter
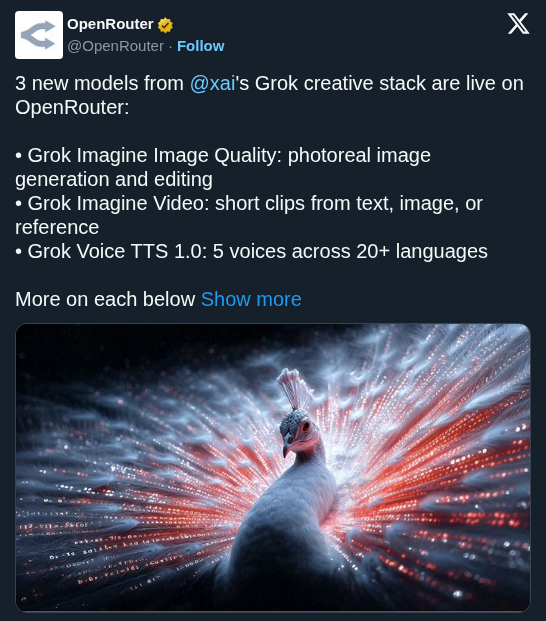
1/ Audio is now first-class on OpenRouter. Two new endpoints live today: 📢 /api/v1/audio/speech — text-to-speech (TTS) 🎤 /api/v1/audio/transcriptions — speech-to-text (SST) Same routing, billing, and keys you already use for text, image, and video. https://t.co/6uHeEUuDl5
26retweets342likes
View on X