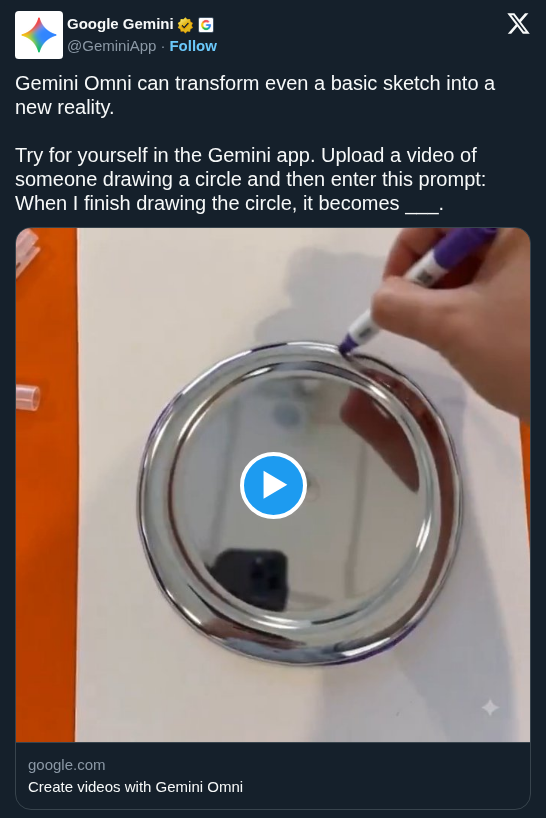
Google DeepMind introduced Gemini Omni Flash, a multimodal model that allows users to transform existing video scenes using natural language prompts. By combining generative media systems with Gemini's reasoning, the model can instantly swap environments or add objects while maintaining the original video's action.
Google DeepMind released Gemini Omni Flash, the first model in a new family designed to unify reasoning with generative media. Unlike standard text-to-video tools, this architecture enables anything-to-anything generation. Users provide a video and describe changes—like altering the background or inserting new elements—that the model executes instantly.
- Model name
- Gemini Omni Flash
- Consumer availability
- Gemini App, Flow by Google, YouTube Shorts
- Developer availability
- API (coming weeks)
- Core capability
- Video-to-video editing and reimagining
- Architecture
- Anything-to-anything multimodal generation
This launch shifts focus from pure generation to semantic video editing and world understanding. While previous releases like Veo 3.1 Lite optimized for production efficiency, Gemini Omni integrates these capabilities directly into the core model loop. It follows the Gemini 3.5 Flash general availability update which optimized the model family for autonomous execution.
You can try Gemini Omni Flash today within the Gemini App, YouTube Shorts, and Flow by Google. For developers, Google plans to roll out API access for the Omni family in the coming weeks. This release follows the launch of Gemini Spark personal agents as Google expands its ecosystem of autonomous, multimodal tools.