Fireworks AI
@FireworksAI_HQ
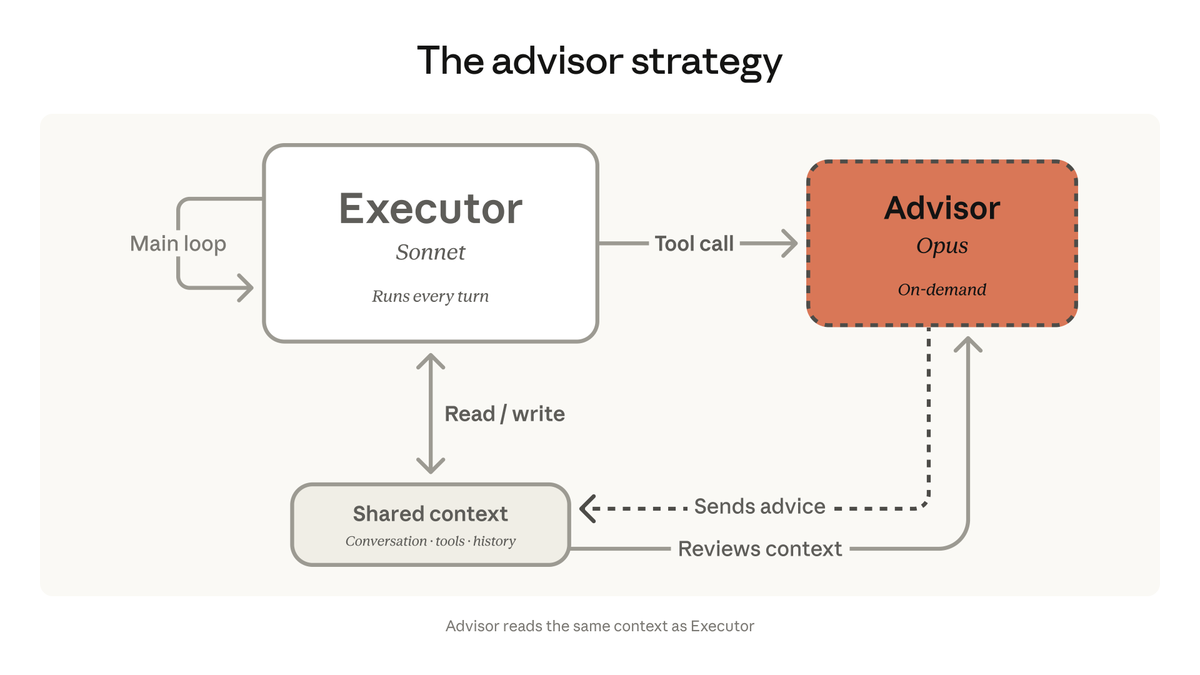
Frontier models are powerful advisors. On @harvey's Legal Agent Benchmark, a GLM 5.1 worker using Claude Opus 4.7 as a sparse advisor reached 18/100 all-pass versus 14/100 for Opus alone, at 39% of the cost. More on the harness design, advisor pattern, and training results: https://t.co/ozxFycdzcT
4retweets22likes
View on X