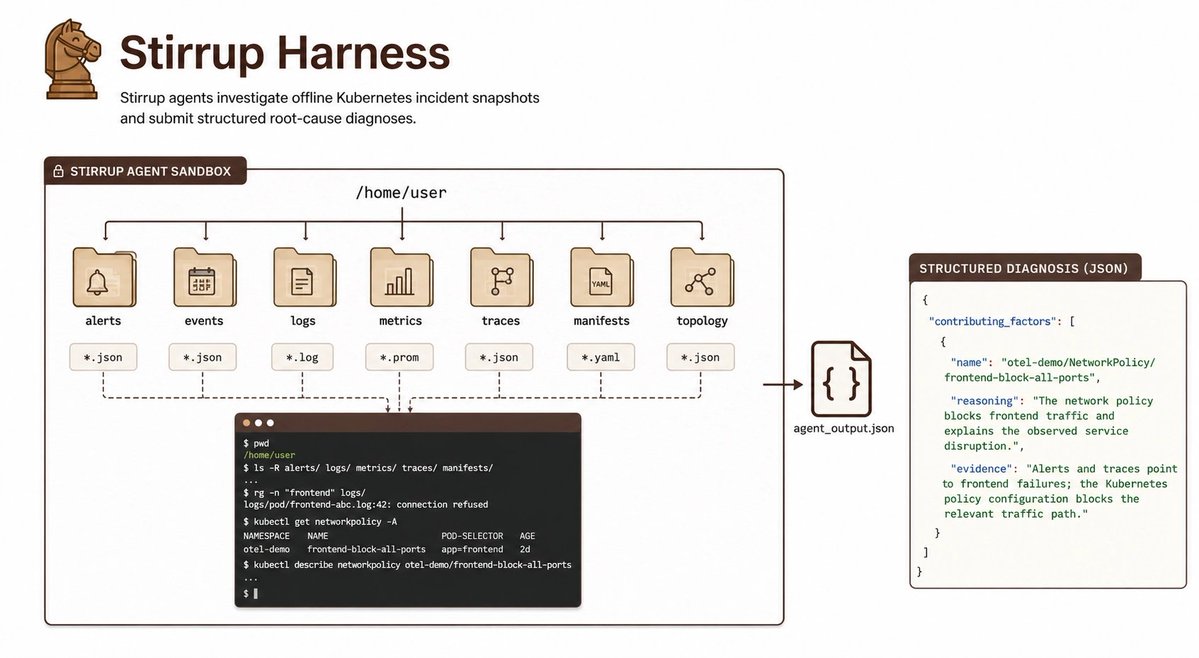
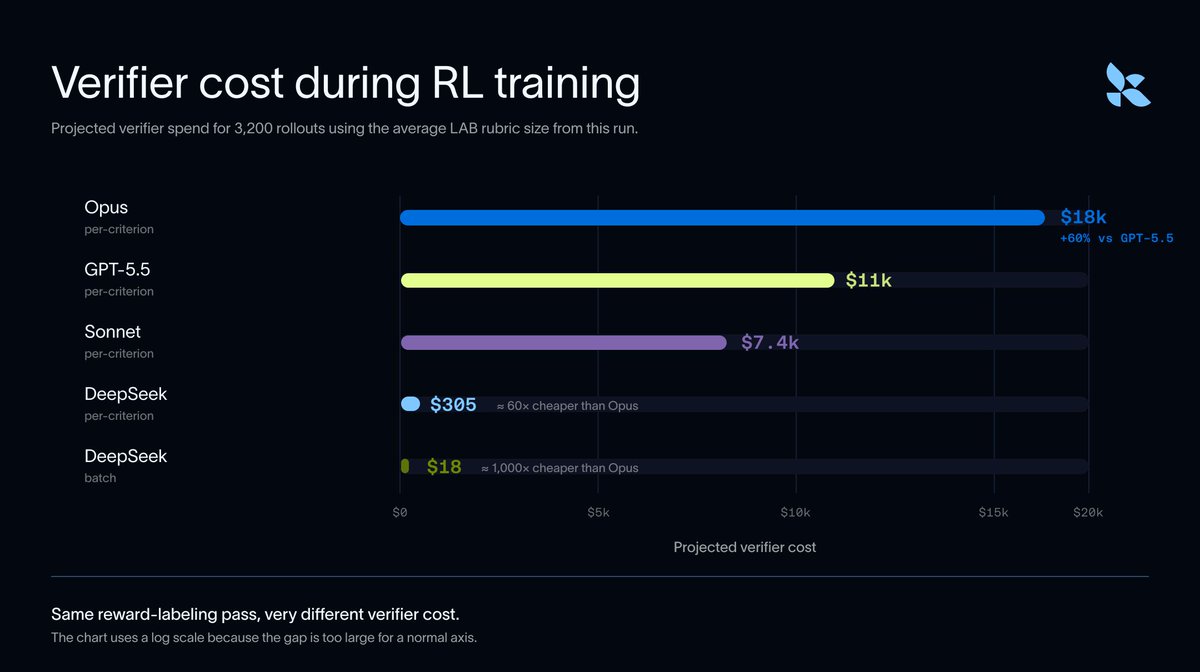
Fireworks AI released a benchmark report on browser agents revealing that malformed outputs create a hidden execution tax that inflates production costs. The study found that reliability in multi-step loops matters more than raw intelligence, with some frontier models wasting nearly a quarter of their inference budget on retries.
Fireworks AI, an inference platform for fast model serving, released a benchmark report revealing a hidden Agent Execution Tax. By running 720 browser tasks, the study found that malformed JSON outputs force silent retries that inflate costs. This tax measures the ratio of wasted inference to productive work.
- Gemini 2.5 Flash execution tax
- 22.9%
- MiniMax M2.5 cost efficiency
- 2.3x cheaper per successful task than Gemini
- Kimi K2.5 retry rate
- 0% across 852 calls
- Benchmark scope
- 720 tasks across 15 websites
- Primary metric
- Reliability-Adjusted Accuracy
This reliability gap shifts focus from raw intelligence to sustained execution in multi-step loops. While models may ace static benchmarks, they often fail in production when malformed responses cascade into higher costs. Alongside Fireworks AI's Day-0 Kimi K2.6 support, this highlights that the serving layer is critical for agentic stability.
You should evaluate models using reliability-adjusted accuracy rather than simple token pricing. For high-volume workloads, MiniMax M2.5 proved 2.3x cheaper than Gemini 2.5 Flash per outcome. Developers can access these models, including GLM 5.1 training, via the Fireworks serverless API to minimize execution overhead.