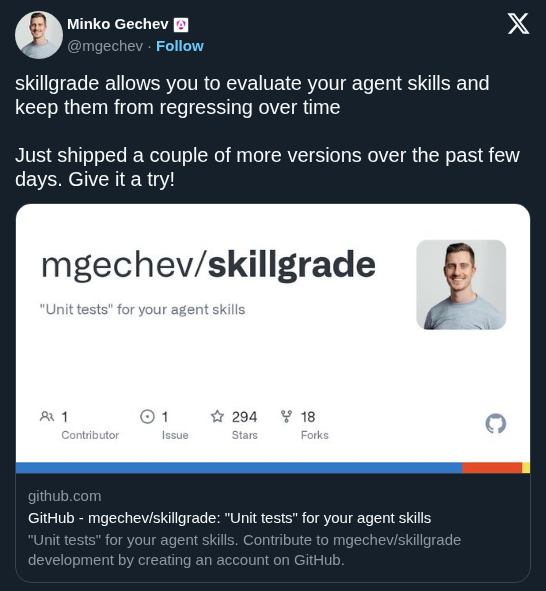
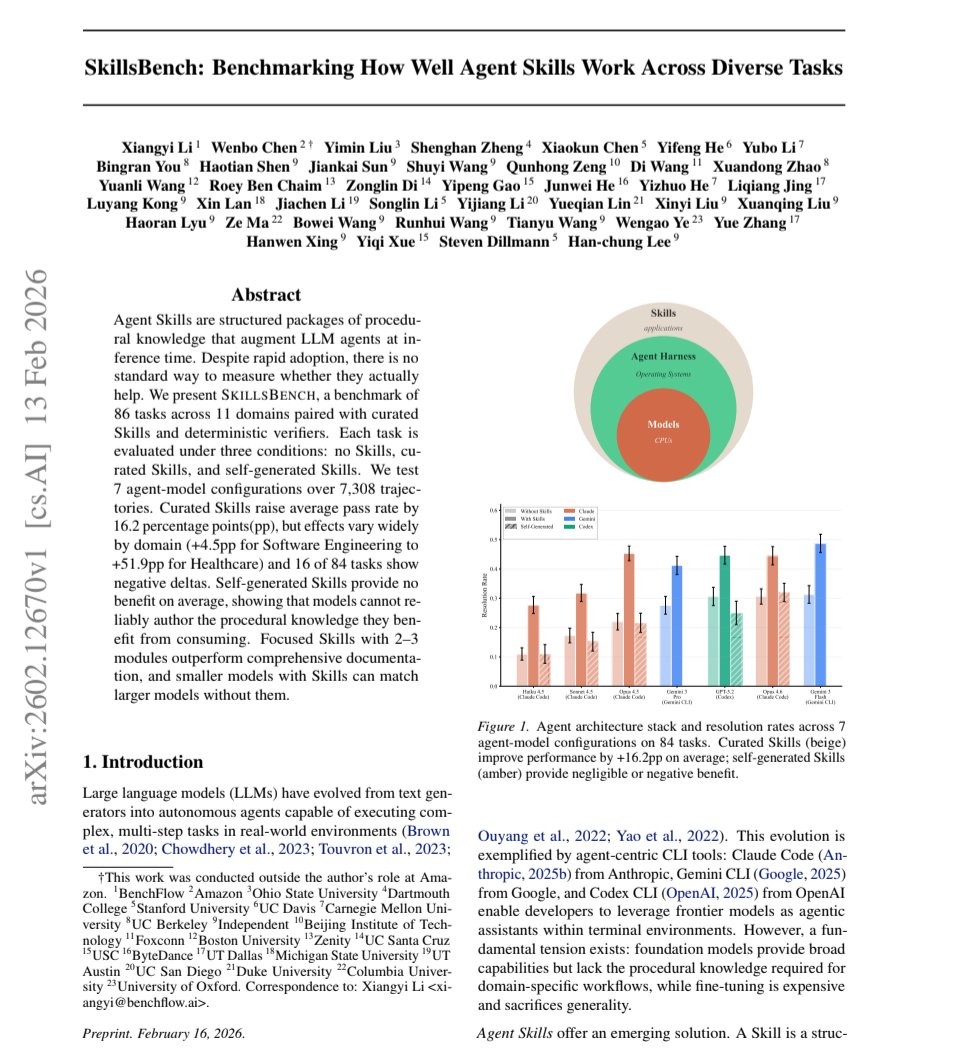
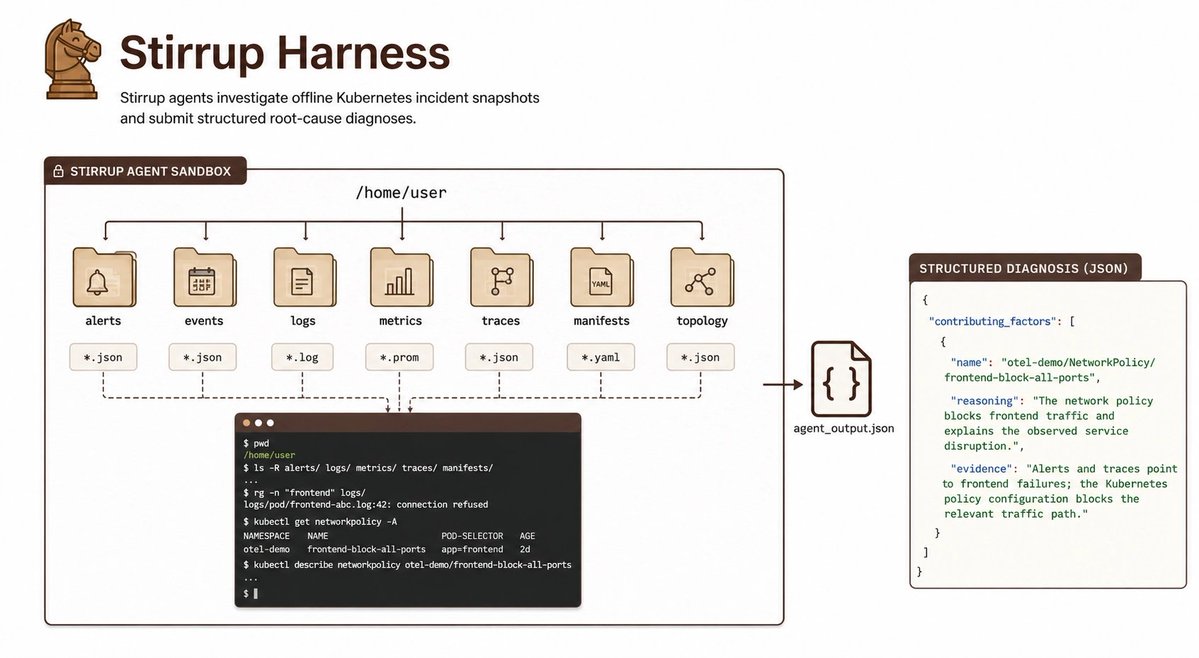
ToolCall-15 open-sourced a benchmark that tests how well local LLMs handle tool calling across 15 scenarios and 12 tools. Built for practitioners shipping agents, it produces deterministic, reproducible results with a live pass/partial/fail dashboard — no research paper required.
ToolCall-15, an open-source benchmark for LLM tool use, runs 15 fixed scenarios against a 12-tool set with mocked responses at temperature 0. The suite covers five categories — Tool Selection, Parameter Precision, Multi-Step Chains, Restraint and Refusal, and Error Recovery — three scenarios each, scored pass/partial/fail. A live dashboard renders the full matrix across OpenRouter, Ollama, and llama.cpp.
Most tool-calling benchmarks are buried in papers with no runnable code or built on abstract cases that don't reflect how agents actually fail. ToolCall-15 is fully inspectable — every prompt, tool definition, expected answer, and scoring rule is published so anyone can verify results.
If you're evaluating local models for an agentic pipeline, this gives you a structured way to test the failures that matter — whether a model picks the right tool, chains steps correctly, and refuses when no tool applies. The repo is MIT-licensed and includes a full methodology document.