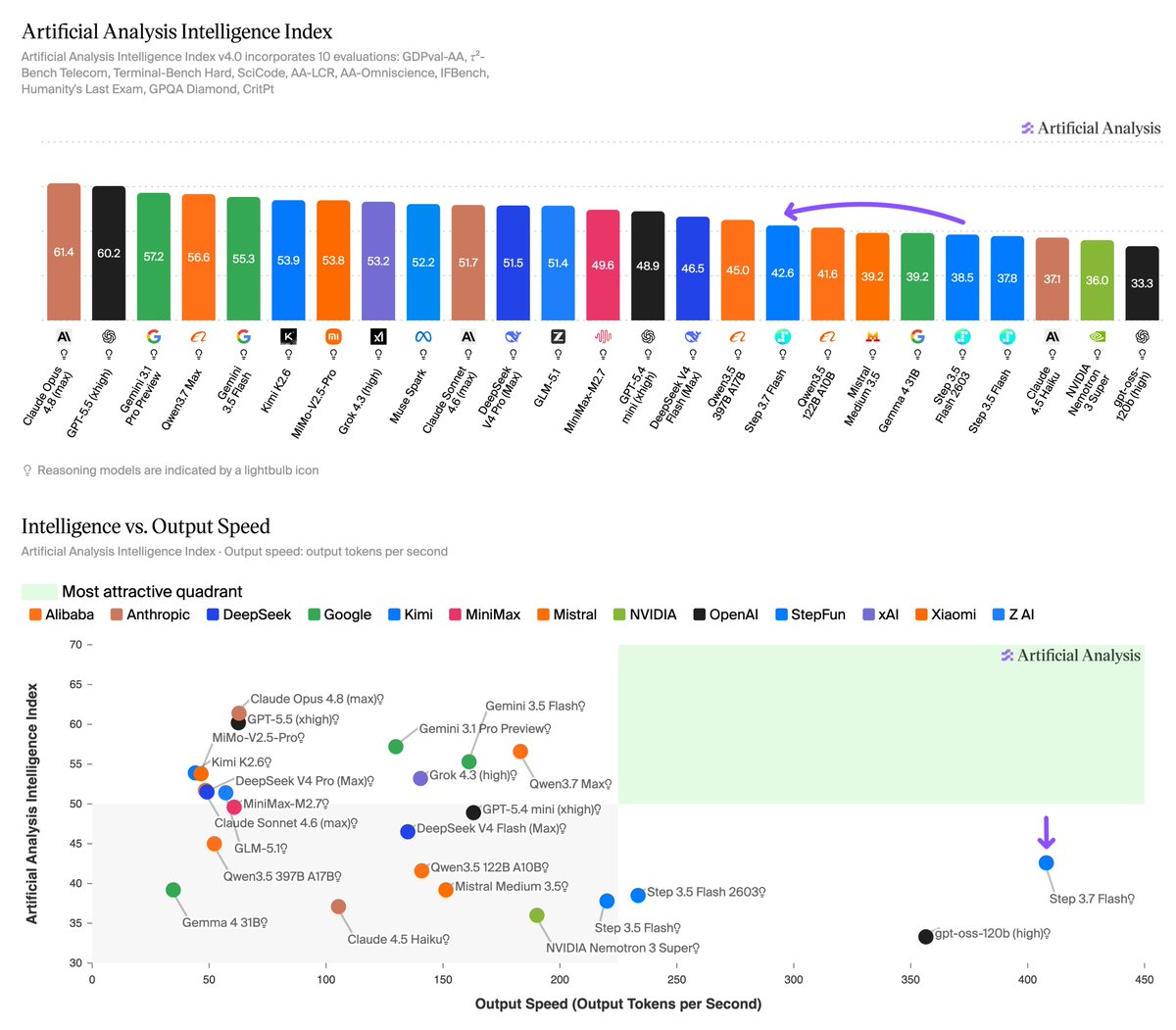
Fireworks AI has deployed Step 3.7 Flash, a 198B-parameter vision-language model designed for rapid inference. The model enables real-time agentic workflows by delivering up to 400 tokens per second with selectable reasoning depths.
Fireworks AI is now hosting Step 3.7 Flash, a 198B-parameter sparse Mixture-of-Experts (MoE) vision-language model (an architecture that activates only a subset of parameters for each task). Developed by StepFun, the model pairs a 196B language backbone with a 1.8B vision encoder for native multimodal understanding.
- Total Parameters
- 198B
- Active Parameters
- 11B
- Throughput
- Up to 400 tokens per second
- Context Window
- 256k tokens
- Reasoning Levels
- Low, Medium, High
This deployment follows the addition of MiniMax M3 to the platform. Engineered for high-frequency production workloads, the model activates only 11B parameters per token despite its massive total count. This sparse activation lets it reach up to 400 tokens per second, enabling real-time agentic loops.
While also available via the Nous Portal integration, the Fireworks deployment offers a 256k context window (the total information a model processes at once). The implementation includes three selectable reasoning levels—low, medium, and high—and uses an Apache 2.0 license.