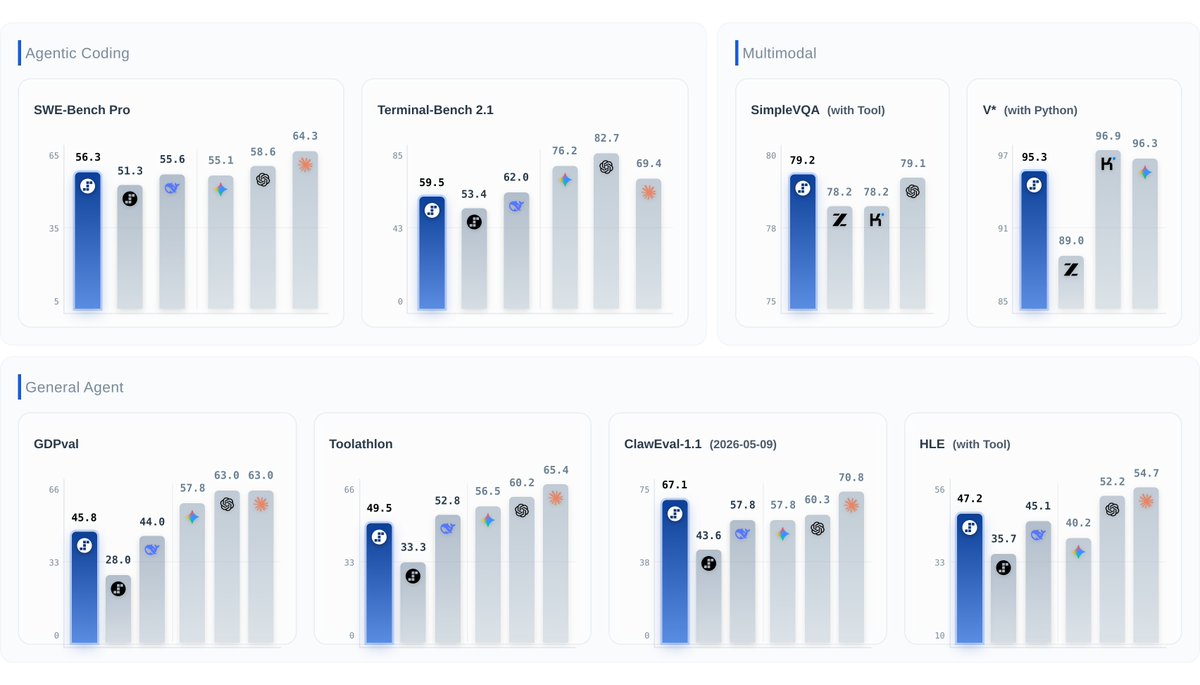
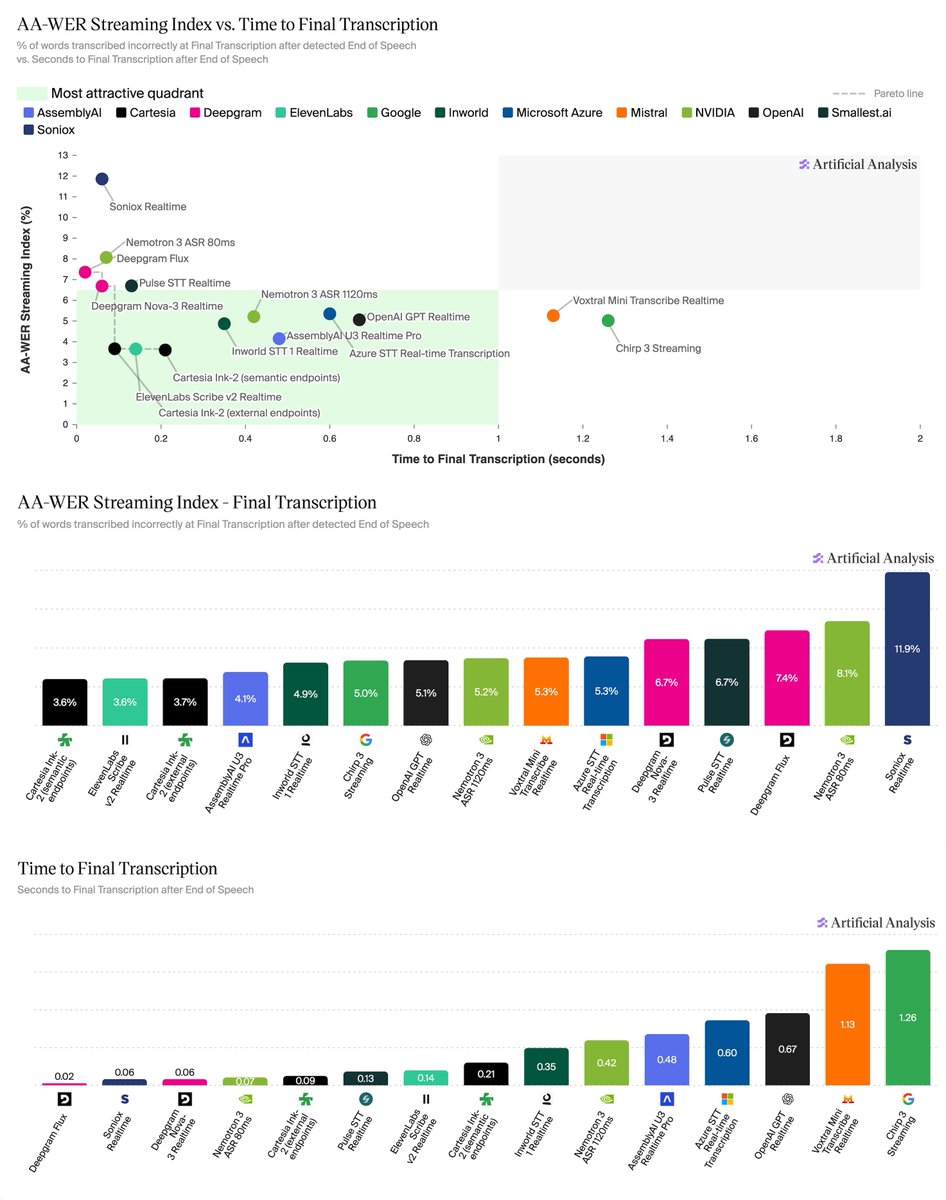
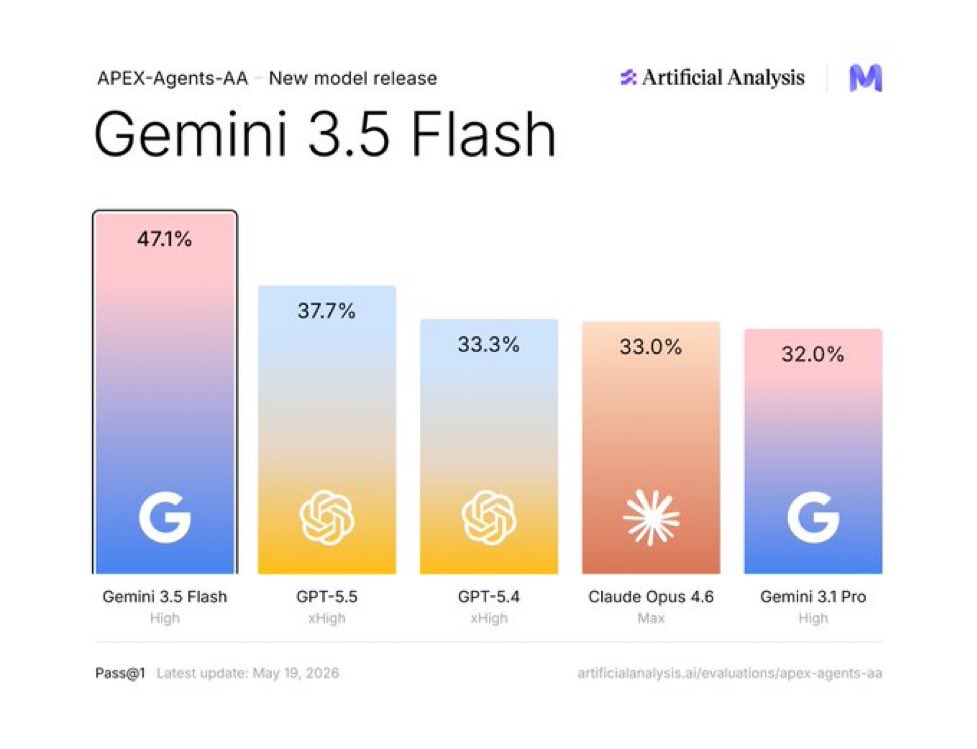
StepFun's Step 3.7 Flash sits on the Intelligence vs Output Speed Pareto frontier, scoring 43 on the Artificial Analysis Intelligence Index and is served at over 400 output tokens/s Step 3.7 Flash (open weights, Apache 2.0) is a significant upgrade on Step 3.5 Flash and stands out for its speed and gains in agentic performance (particularly GDPval-AA). 400 output tokens/s is more than double other models of a similar size class. Contributing to this speed is that the model has only 11B active parameters and the model ships with trained Multi-Token Prediction heads (3) that predict several tokens in a single forward pass, letting it decode multiple tokens at once using speculative decoding. Key results for Step 3.7 Flash with the high reasoning level: ➤ 4 point Intelligence Index improvement: Step 3.7 Flash scores 42.6 on the Artificial Analysis Intelligence Index, up 4 points from Step 3.5 Flash 2603 (38.5). It is equivalent to Qwen3.5 122B A10B (41.6) and trails MiniMax-M2.7 (49.6) and DeepSeek V4 Flash (Max Effort, 46.5) ➤ Speed-intelligence frontier: Step 3.7 Flash achieves ~400 output tokens/s on StepFun's first-party API, placing the model on the Intelligence vs Output Speed Pareto frontier. StepFun has released the weights for this model and we expect several third-party providers to serve this model ➤ Agentic capability improvements: Step 3.7 Flash improves over Step 3.5 Flash 2603 across our agentic evaluations, in both GDPval-AA (real-world agentic tasks) and TerminalBench Hard (agentic coding and terminal use). It achieves a GDPval-AA Elo of 1298, up from 1070 for Step 3.5 Flash 2603, and it's TerminalBench Hard score increases to 35.6% from 32.6%. AA-LCR (Long Context Reasoning) improves to 63.7% from 54.3%. Scores for other evals remain relatively flat ➤ Weaker on knowledge and hallucination than peers: While Step 3.7 Flash trails competitors overall on AA-Omniscience (-38), it improves from Step 3.5 Flash 2603 (-44). It has an AA-Omniscience accuracy of 25.4% and a hallucination rate of 84.4% ➤ Native multimodal support, new in this generation: Step 3.7 Flash introduces a 1.8B-parameter vision encoder for native image understanding, where Step 3.5 Flash was text-only. On MMMU-Pro (multimodal reasoning) it scores 75.3%, roughly matching Qwen3.5 122B A10B (75.0%). Among its same-size open weights peers, MiniMax-M2.7, DeepSeek V4 Flash, and gpt-oss-120b are text-only Key model details: ➤ Context window: 256K tokens ➤ Parameters: 198B total, 11B active (MoE). At BF16 native precision, Step 3.7 Flash requires ~400GB to store the weights. StepFun has also released FP8 (~200GB) and NVFP4 (~100GB) versions for lower-memory deployment ➤ License: Apache 2.0 ➤ Availability: Currently Step 3.7 Flash is available on @StepFun_ai 's first-party API
Artificial Analysis finds Step 3.7 Flash sets a new speed intelligence frontier
· Updated
Artificial Analysis has released independent benchmarking for StepFun's Step 3.7 Flash, confirming the model delivers over 412 output tokens per second. The results place the open-weights model on the Pareto frontier for speed versus intelligence, showing significant gains in autonomous agentic tasks.
- Intelligence Index
- 43
- Output Speed
- 412.1 tokens/s
- Active Parameters
- 11B
- Total Parameters
- 198B
- Context Window
- 256K tokens
This performance places Step 3.7 Flash on the Pareto frontier, doubling the speed of similarly sized peers. While it trails Claude Opus 4.8 on the Intelligence Index, it posts major gains in agentic work — improving from 1070 to 1298 on Artificial Analysis's GDPval-AA evaluation over the prior Step 3.5 Flash. On multimodal reasoning, it scores 75.3% on MMMU-Pro, roughly matching Qwen3.5 122B A10B.
The model is available under an Apache 2.0 license with a 256K context window and native image understanding. Weights are on Hugging Face, with API access at $0.18 per million tokens. Providers like Nous Research have already integrated Step 3.7 Flash for high-efficiency agentic coding.
Every HeadsUpAI update is written based on its original source and reviewed before it's published. Read our editorial standards →