MiniMax (official)
@MiniMax_AI
M3 on Cloudflare AI Gateway, day one ⚡ Frontier coding, 1M context, and native multimodal and now just one fetch away. It is time to build something. 🦞
1retweets93likes
View on X· Updated
Cloudflare has integrated the MiniMax M3 foundation model into its AI Gateway platform. The update provides developers with a high-context, multimodal model specialized for autonomous coding tasks directly within their existing infrastructure.
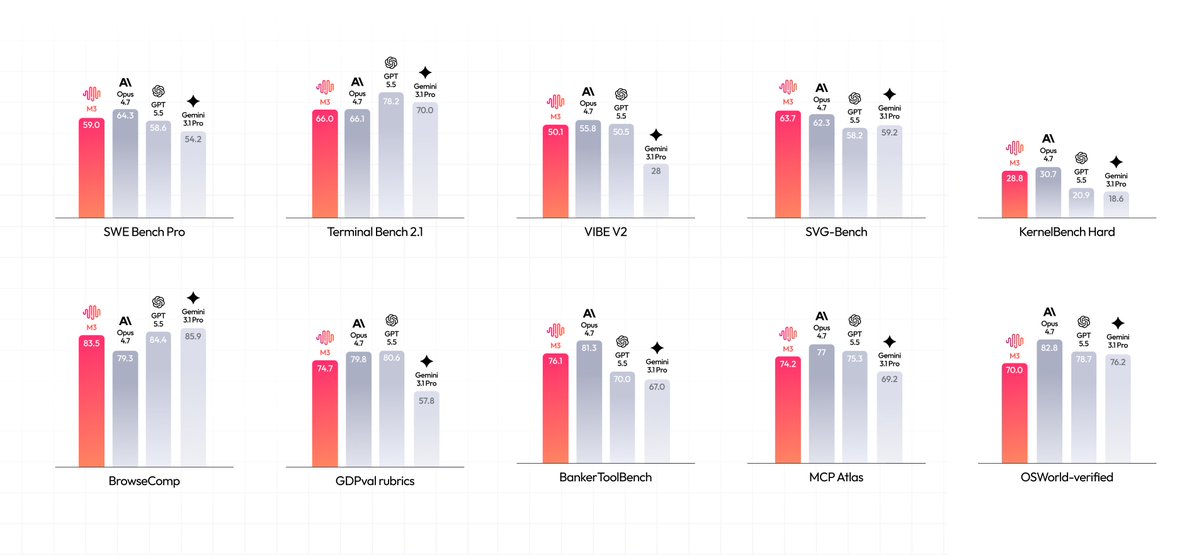
Hosting a model with frontier coding performance provides a specialized alternative to general-purpose proprietary systems. This move follows a pattern of high-context models reaching developer gateways, such as the Qwen3.5-Plus update on Vercel, and joins Vercel's MiniMax M3 integration in expanding access to 1M-context workflows. It positions M3 as a competitor to other 1M-context models like the DeepSeek-V4 release that target autonomous development across massive codebases.
Developers can access minimax-m3 via the AI Gateway now. This availability targets teams building agentic workflows that require processing large repositories or long-form documents without managing their own model infrastructure.
M3 on Cloudflare AI Gateway, day one ⚡ Frontier coding, 1M context, and native multimodal and now just one fetch away. It is time to build something. 🦞
Still wondering? A few quick answers below.
Every HeadsUpAI update is written based on its original source and reviewed before it's published. Read our editorial standards →
More like this