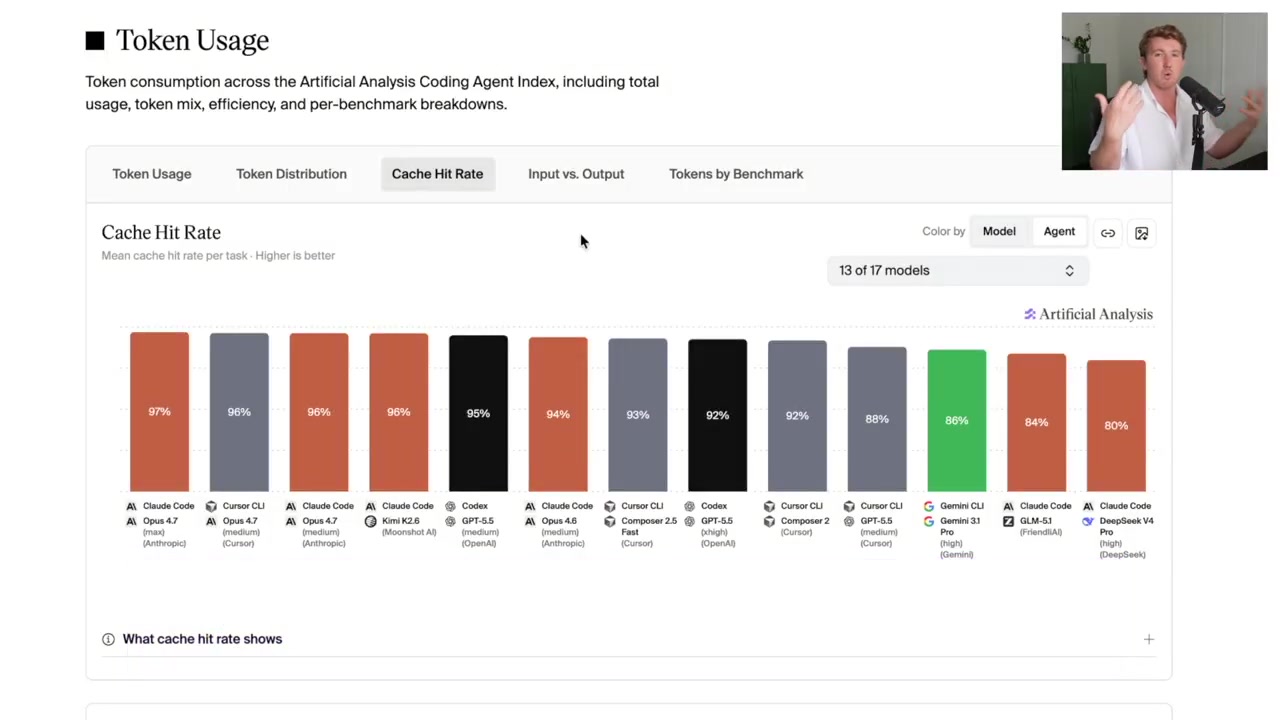
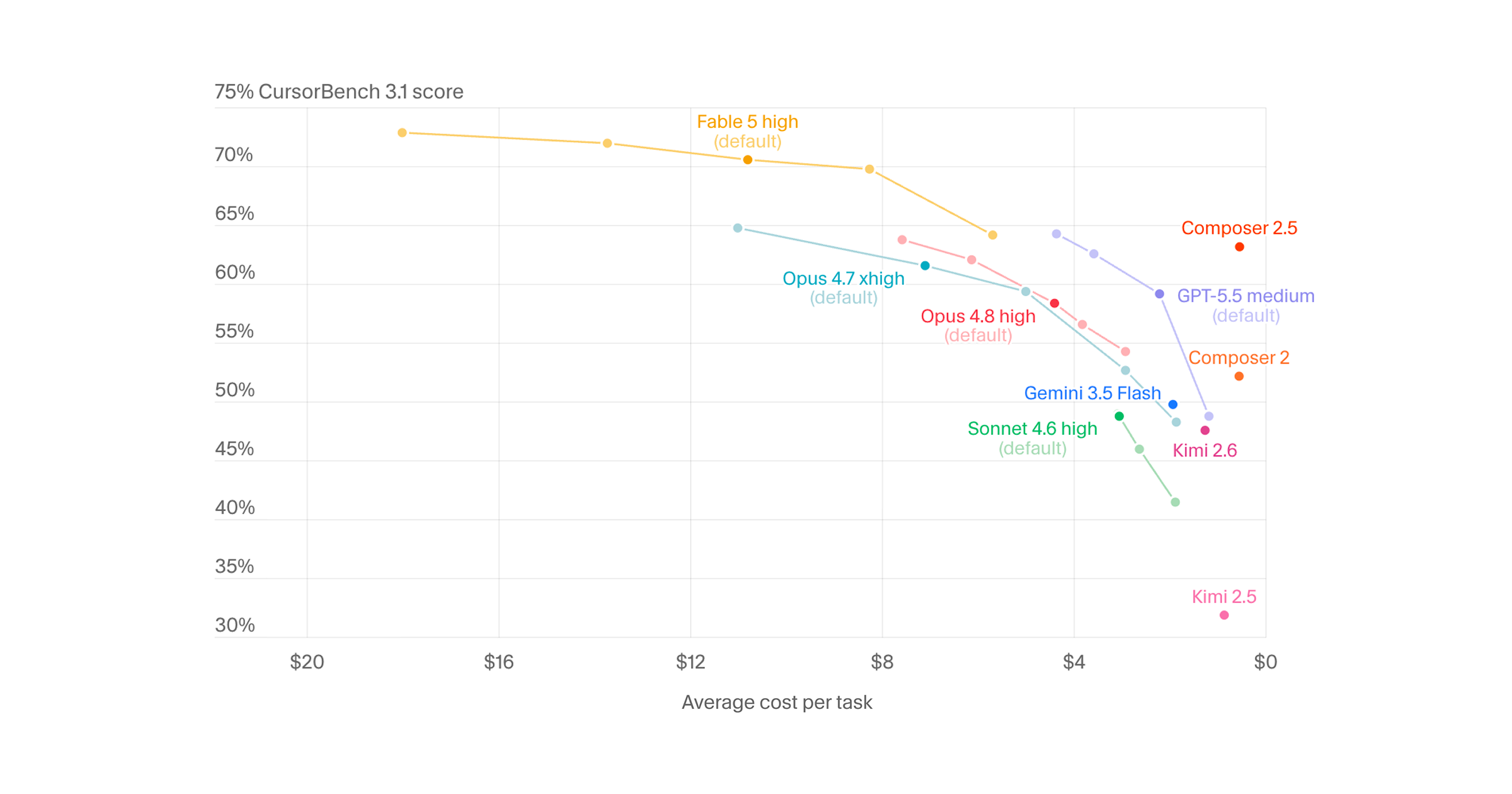
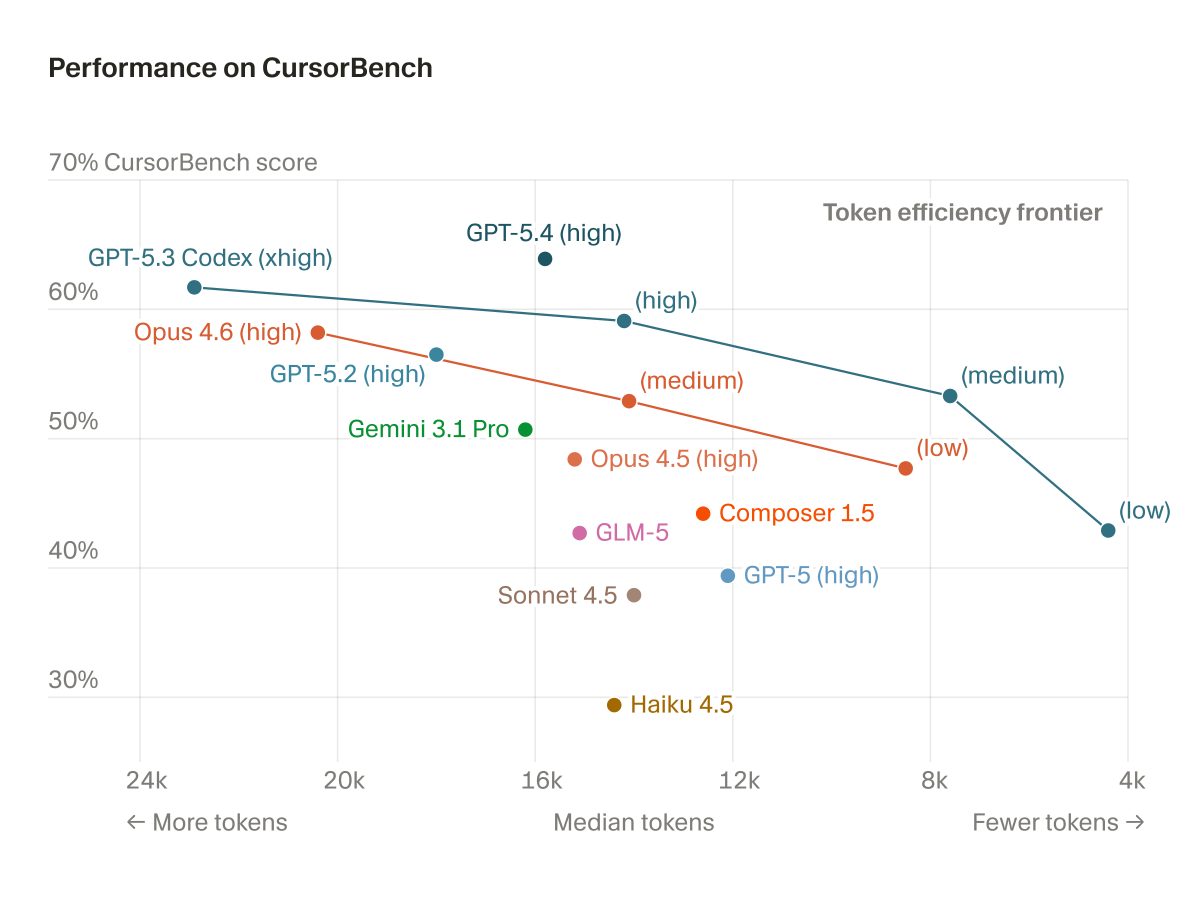
We've updated the Artificial Analysis Coding Agent Index, replacing SWE-Bench Pro with Datacurve's DeepSWE benchmark - the swap lifts Codex with GPT-5.5 (xhigh) above Claude Code with Opus 4.8 (max), while the newly released Claude Fable 5 (max) in Claude Code debuts at the top DeepSWE, built by @datacurve, writes its tasks from scratch rather than adapting them from public GitHub issues or pull requests, so no model has seen the solutions during training. That matters because SWE-Bench Pro, the benchmark it replaces in our Coding Agent Index, had grown gameable, with some models recovering the fix from the repository's commit history instead of solving the task. The swap reorders the index: Codex with GPT-5.5 (xhigh) rises from 65 to 76, overtaking Claude Code with Opus 4.8 (max) at 73. Claude Code with Fable 5 (max), which enters directly on the refreshed index, leads at 77. SWE-Bench Pro had been flattering some combinations and penalizing others. More below.
Artificial Analysis Updates Coding Agent Index with Contamination-Proof DeepSWE Benchmark
Artificial Analysis updated its Coding Agent Index to v1.1, replacing the gameable SWE-Bench Pro with Datacurve's DeepSWE. DeepSWE tasks are written from scratch to prevent training data contamination. The refreshed leaderboard ranks Claude Code with Fable 5 at 77, followed by Codex with GPT-5.5 at 76 and Claude Code with Opus 4.8 at 73.
Artificial Analysis
@ArtificialAnlys
185retweets1.9klikes
View on XEvery HeadsUpAI update is written based on its original source and reviewed before it's published. Read our editorial standards →