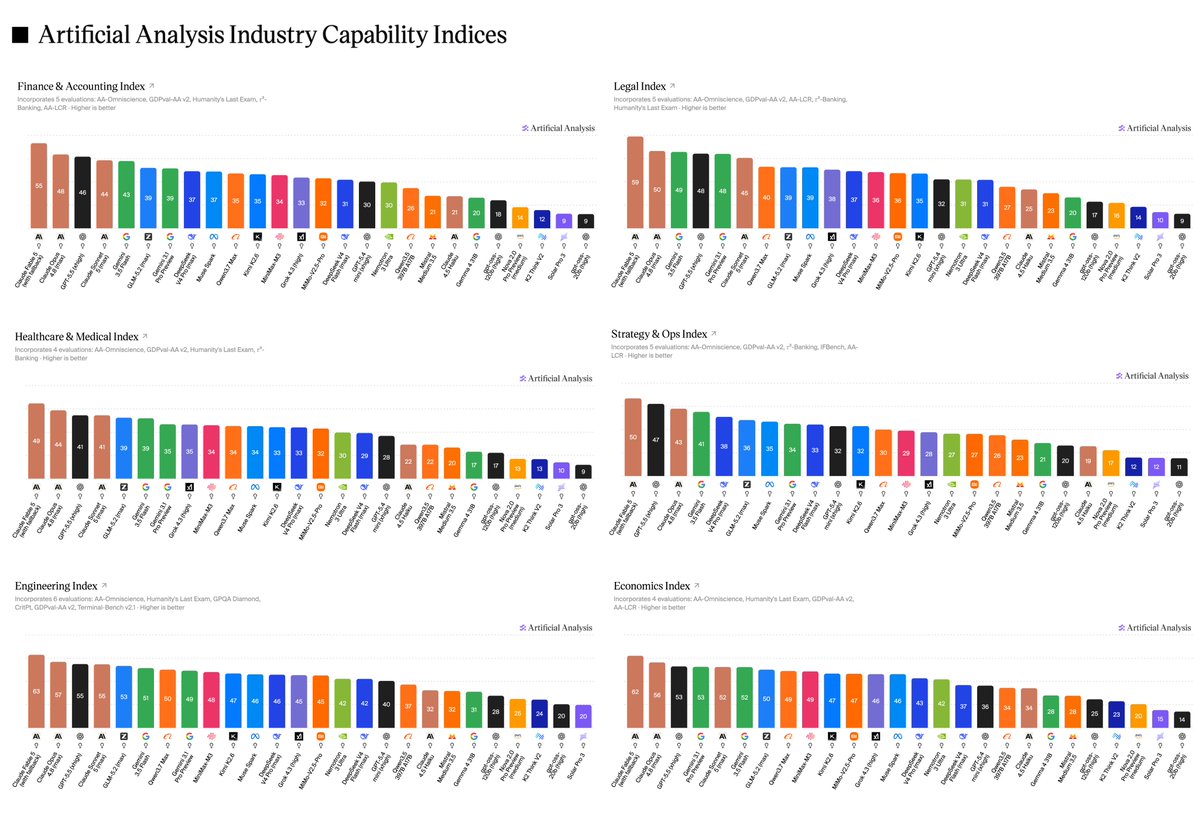
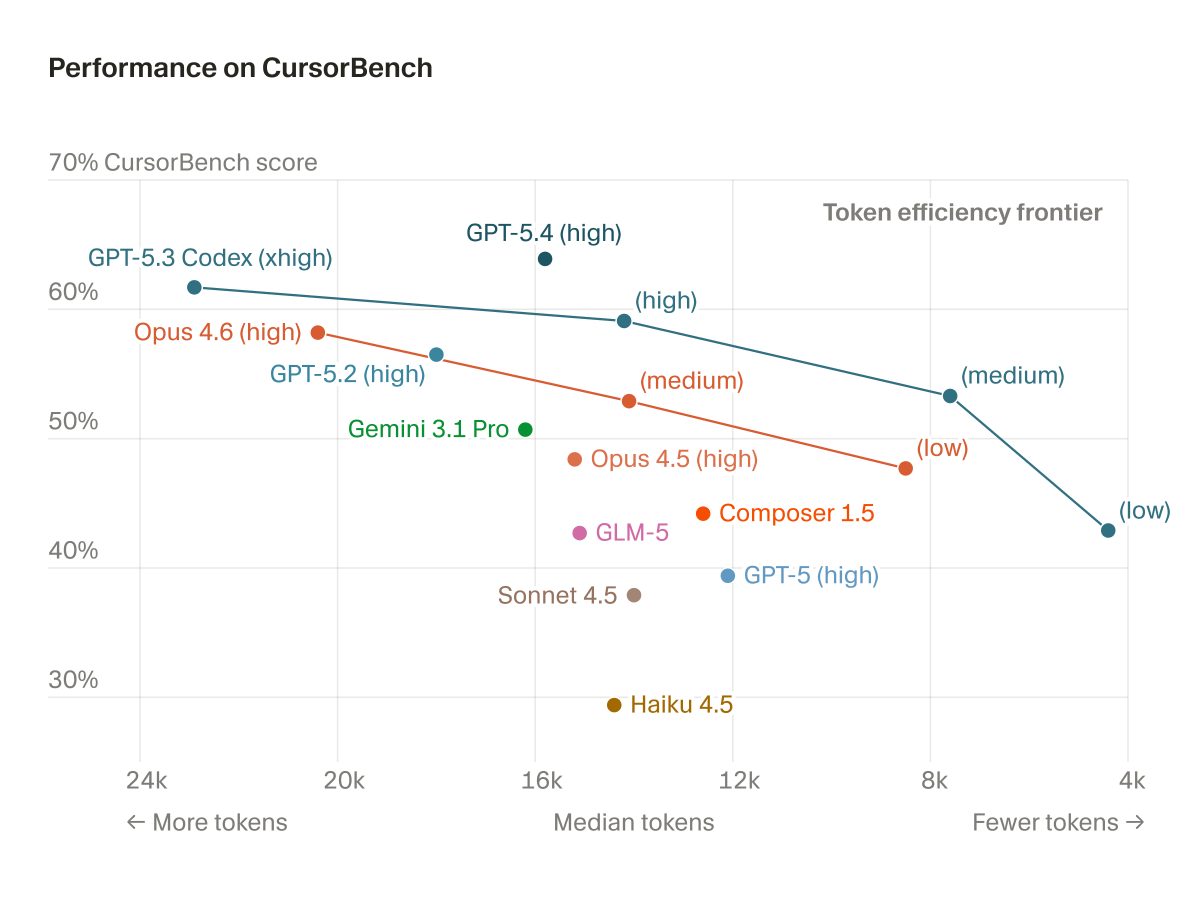
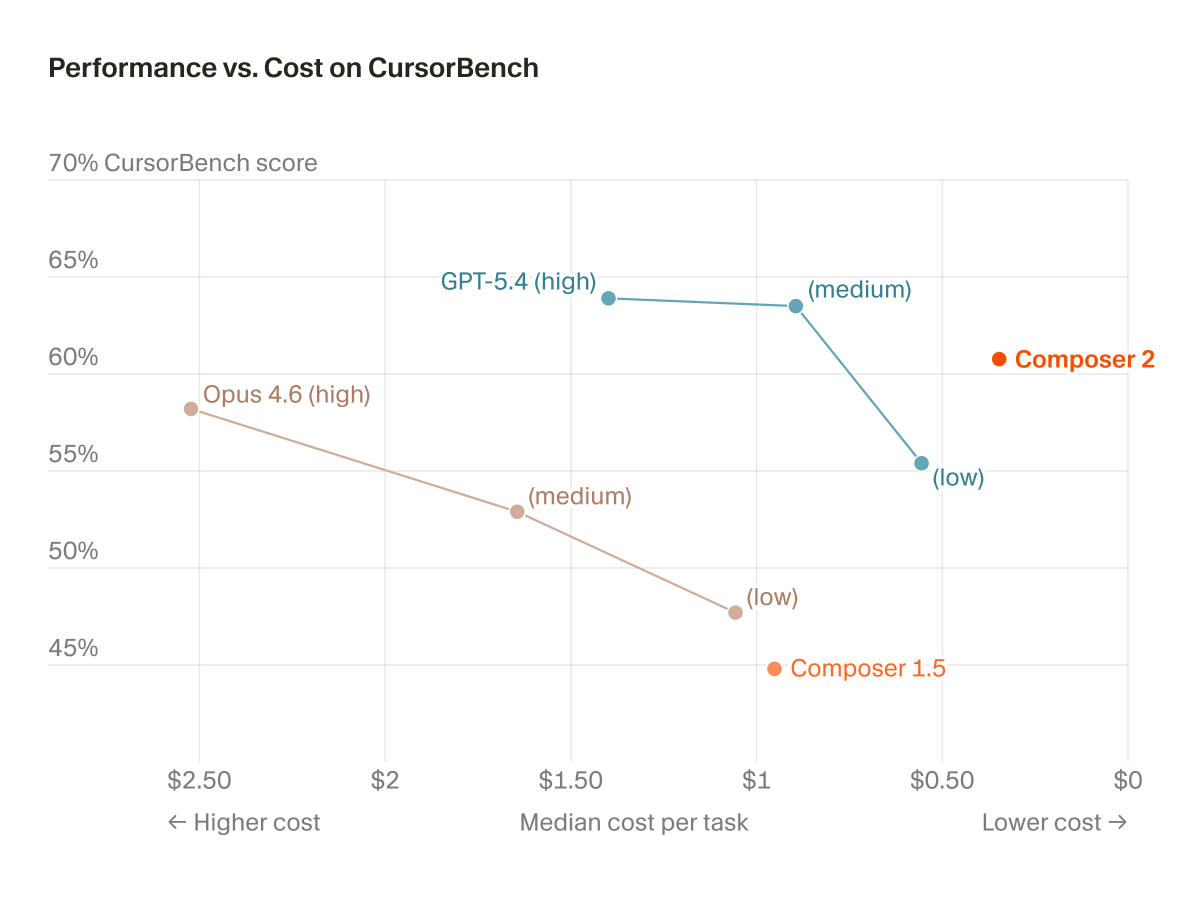
Artificial Analysis has released a specialized benchmarking suite and index for autonomous coding agents. The initial data identifies Claude Code as the performance leader while highlighting Cursor’s Composer 2.5 as a top-tier option for cost-efficiency.
Artificial Analysis has launched a dedicated Coding Agent Index to evaluate the performance, cost, and speed of autonomous programming tools. The benchmark measures agent loops—iterative cycles where an AI observes an environment, reasons, and executes actions—to provide a standardized comparison of how these systems handle complex software engineering tasks.
- Performance Leader
- Claude Code (Opus 4.7)
- Cost-Efficiency Leader
- Cursor Composer 2.5
- Evaluation Metrics
- Performance, Cost, Token Usage, and Speed
- Analysis Format
- Coding Agent Index and YouTube walkthroughs
The index identifies Claude Code, running on Opus 4.7, as the current leader in raw performance. It also highlights the Composer 2.5 release as a significant entry on the cost-performance frontier, offering a high-capability alternative at a lower price point. This independent data helps teams navigate the trade-offs between model intelligence and the operational expense of multi-step agentic workflows.
Developers can use these rankings to select agents based on specific project requirements, such as prioritizing execution speed or minimizing token usage. The benchmarks complement existing CursorBench evaluations by providing third-party verification across different providers. Detailed walkthroughs of the performance and cost data are available on the company's new YouTube channel.