Qwen
@Alibaba_Qwen
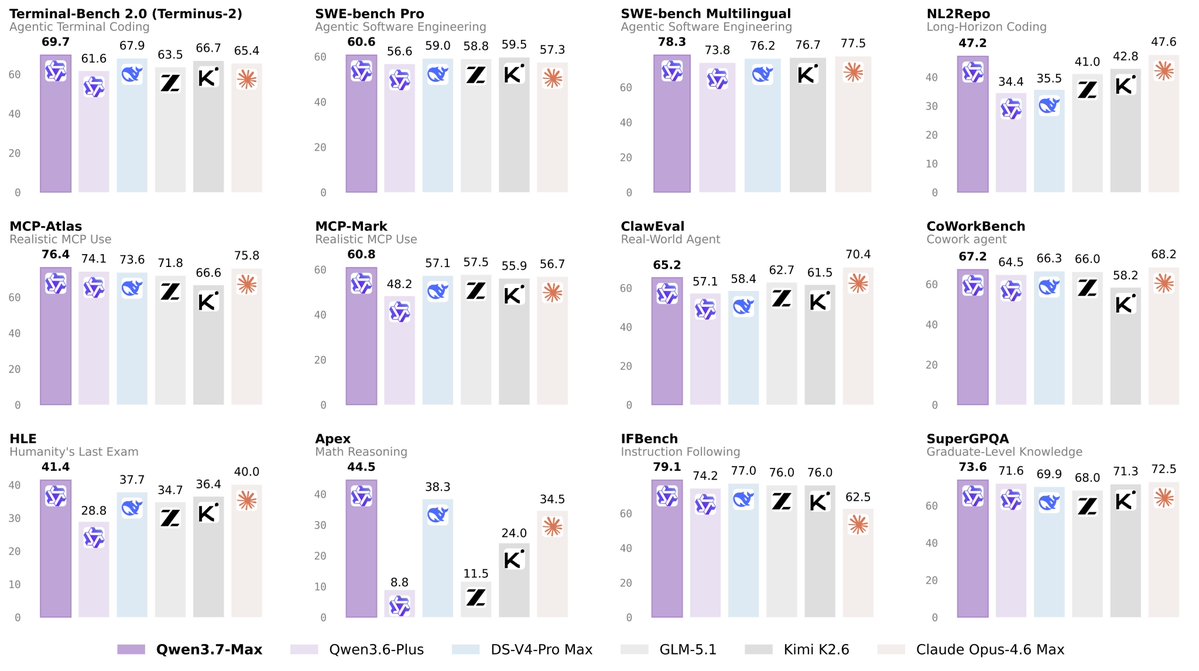
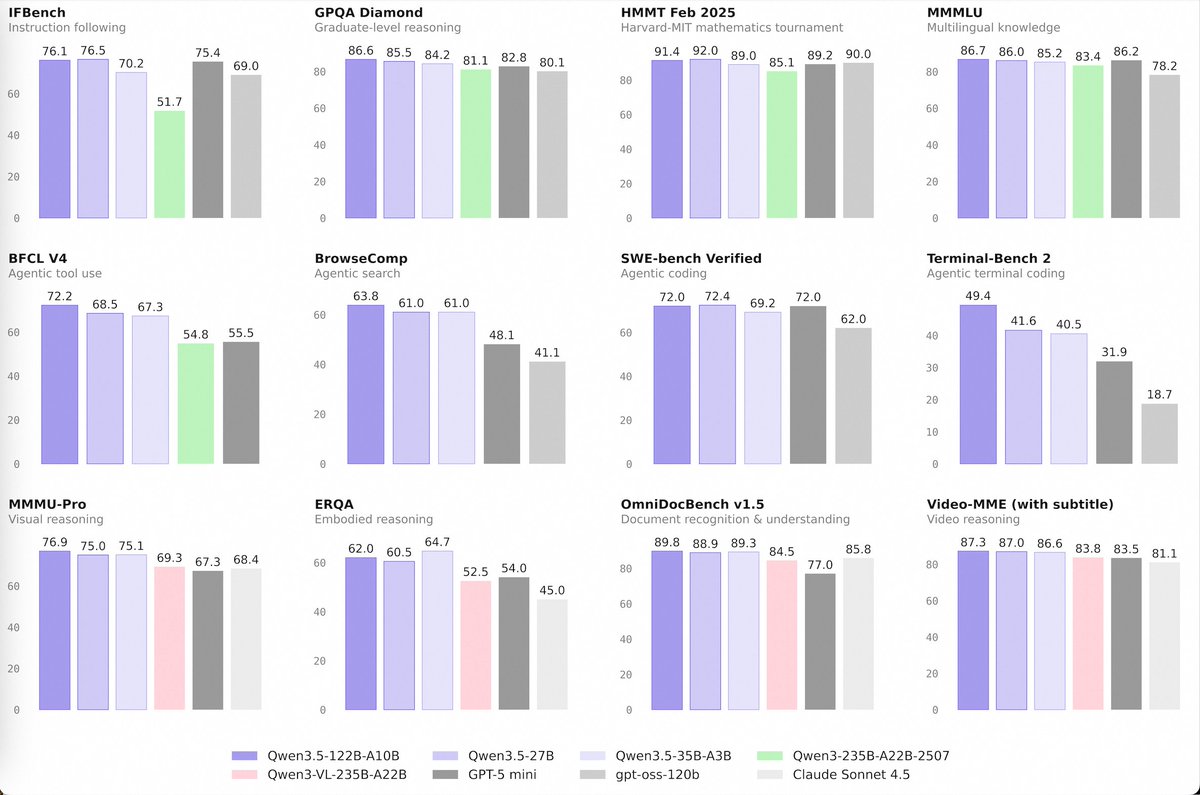
✅Implicit caching is now live on Qwen3.7-Max — kicks in automatically, no setup needed. ⚡️Faster + cheaper out of the box. Need higher, more deterministic hit rates? Try explicit caching instead. 🙌 🔗Best practices 🔗 :https://t.co/3hSs6zquBH
101retweets1.4klikes
View on X