OpenRouter
@OpenRouter
Three new @MicrosoftAI models now live on OpenRouter! Launching together: MAI-Image-2.5, MAI-Transcribe-1.5, and MAI-Voice-2. More on each below 🧵 https://t.co/KD5JlX6DT6
3retweets40likes
View on X· Updated
OpenRouter has integrated Microsoft’s new in-house MAI-Image-2.5, MAI-Transcribe-1.5, and MAI-Voice-2 models into its unified API. These models provide a high-performance stack for image, speech, and voice tasks built entirely without third-party distillation.
MAI-Image-2.5 for generation and editing, MAI-Transcribe-1.5 for speech-to-text, and MAI-Voice-2 for expressive text-to-speech. These models are built without distillation—training a smaller model to mimic a larger one—to ensure original performance.This integration follows the recent MAI-Image-2.5 debut on the Arena image leaderboard. By hosting these on OpenRouter, Microsoft makes its frontier-grade media capabilities accessible outside of Azure. This move follows how OpenRouter previously added the xAI creative stack to provide a single endpoint for multimodal workflows.
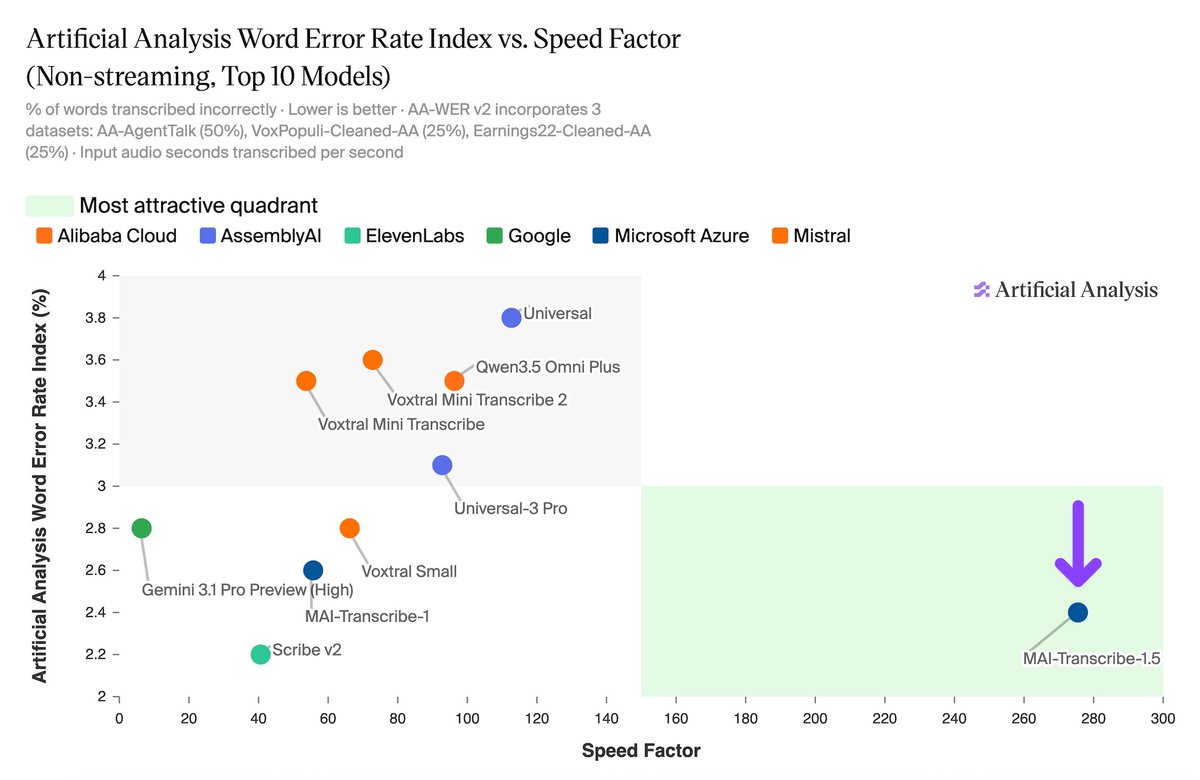
Developers can now use the OpenRouter API for production-grade audio and visual tasks. MAI-Transcribe-1.5 transcribes an hour of audio in under 15 seconds, while MAI-Voice-2 offers emotional controls like whispering. These models are available now alongside hundreds of others via a unified API.
Three new @MicrosoftAI models now live on OpenRouter! Launching together: MAI-Image-2.5, MAI-Transcribe-1.5, and MAI-Voice-2. More on each below 🧵 https://t.co/KD5JlX6DT6
Still wondering? A few quick answers below.
Every HeadsUpAI update is written based on its original source and reviewed before it's published. Read our editorial standards →
More like this