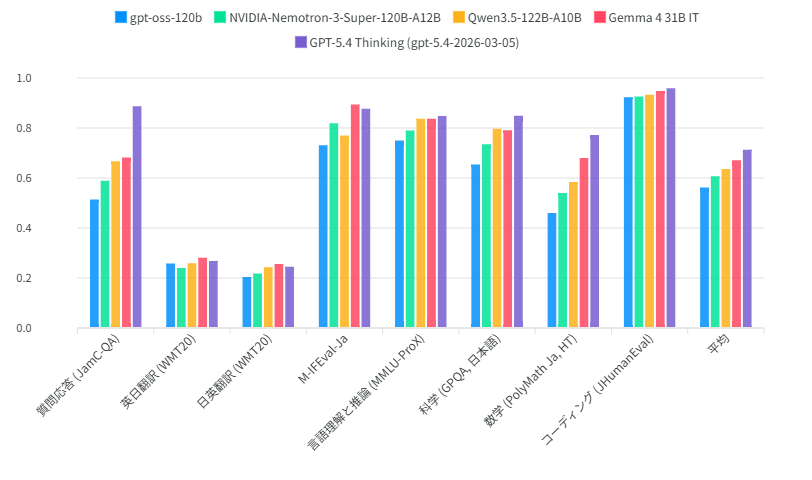
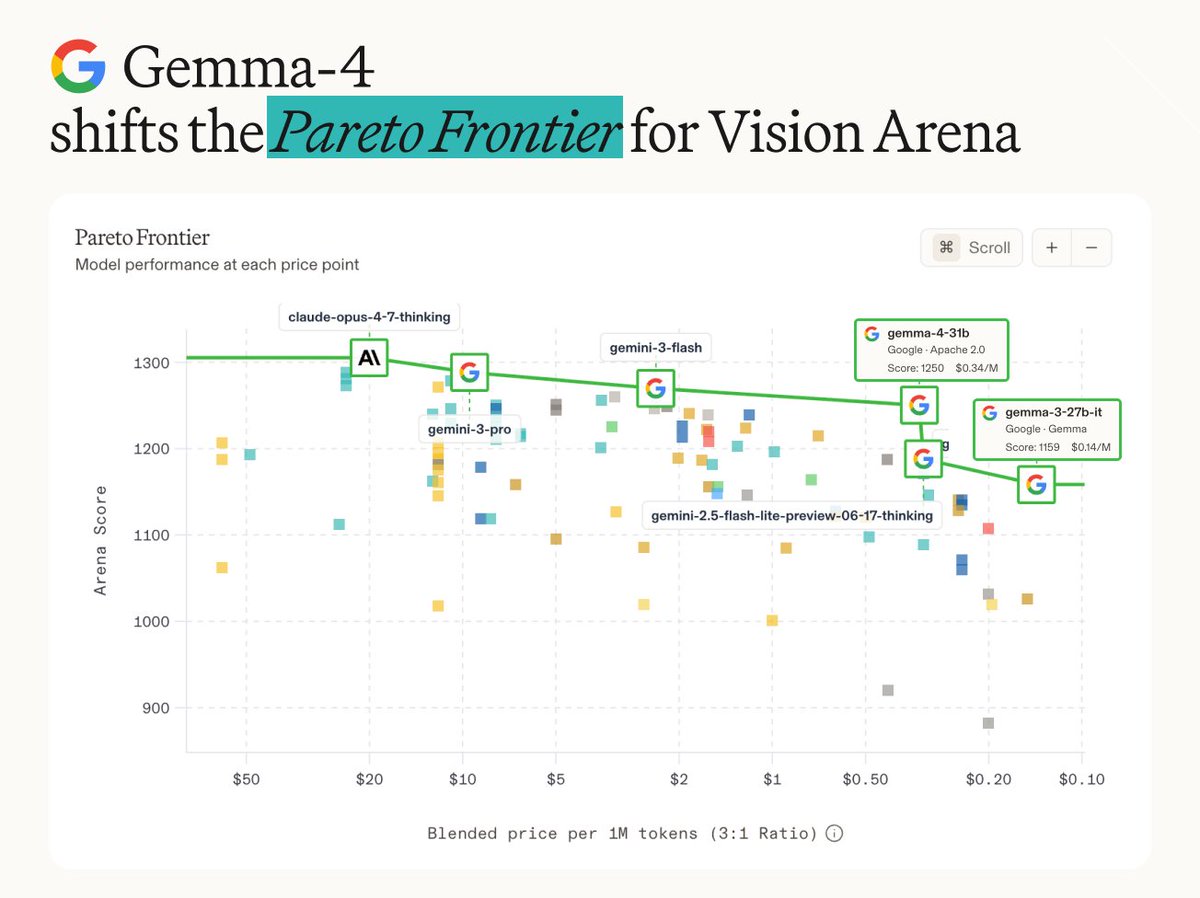
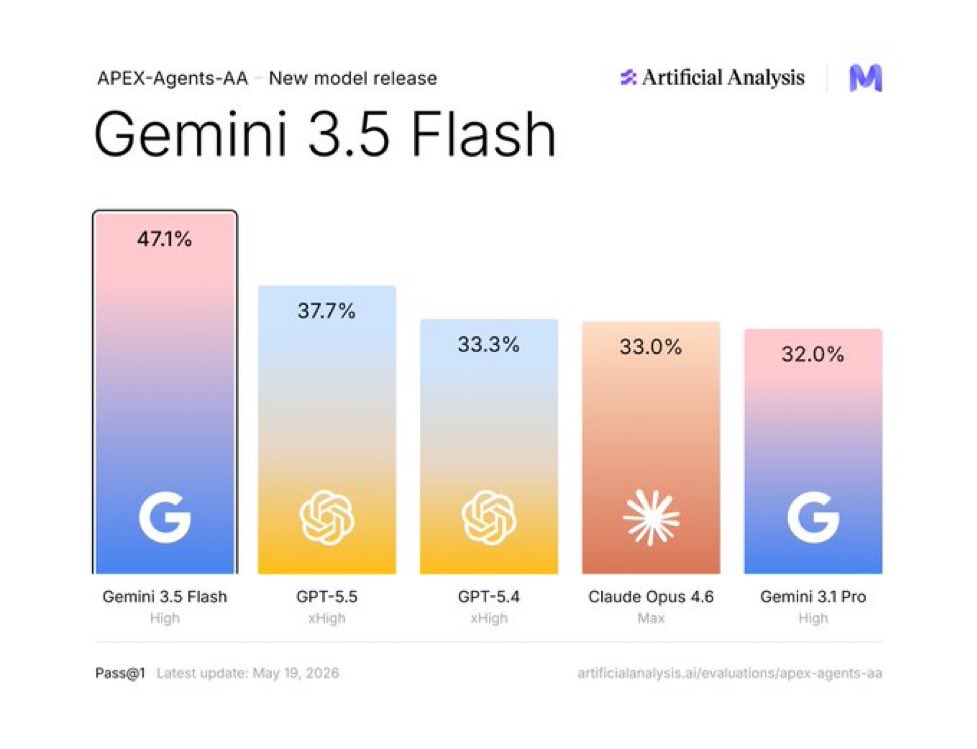
Google's Gemma 4 31B ranked as the top-performing open-weight model on TERMS-Bench, a new evaluation for AI agents conducting economic negotiations. The benchmark uses a verifiable environment instead of LLM grading to measure an agent's ability to maximize profit while following strict financial constraints.
Google's Gemma 4 31B achieved the highest score among open-weight models on TERMS-Bench, a diagnostic benchmark for AI agents (autonomous systems that plan and act independently). Unlike 'LLM-as-judge' grading, this framework uses a deterministic environment to verify if an agent maximizes surplus (the available bargaining profit) while obeying price bounds.
- Benchmark (TERMS-Bench SE+)
- 0.640
- Agreement rate (AGR+)
- 99.8%
- Open-weight rank
- #1
- Parameters
- 31 billion
- Availability
- Open weights, Google API
Negotiation represents a high-stakes reasoning shift for agentic AI, requiring models to maintain internal beliefs about an opponent's hidden constraints. This performance validates Gemma 4 31B as a viable alternative to proprietary systems. It follows Gemma 4's top vision rankings, cementing its position as a frontier-class open model.
You can use Gemma 4 31B for autonomous procurement or marketplace workflows where maximizing financial utility is critical. The model's high surplus efficiency suggests it can secure better deals than larger proprietary models at lower cost. The 31B model is available as an open-weight release or via the Google API.