Cursor
@cursor_ai
We're releasing a technical report describing how Composer 2 was trained. https://t.co/cfW8lyMWEy
364retweets
View on X· Updated
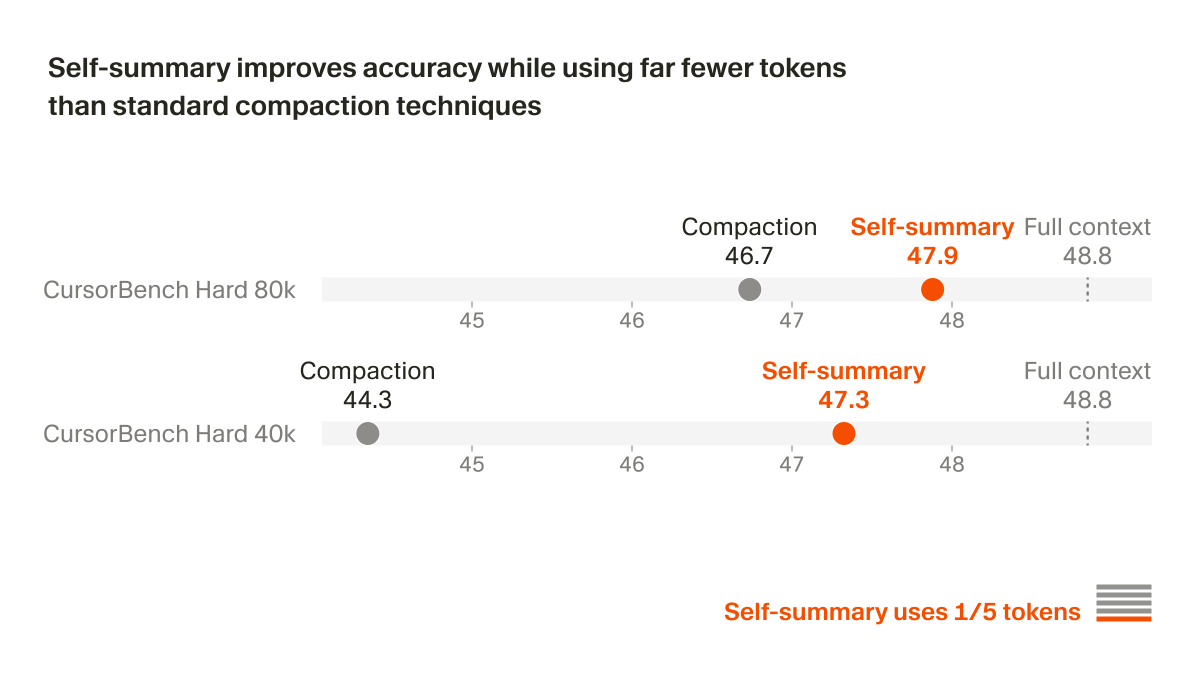
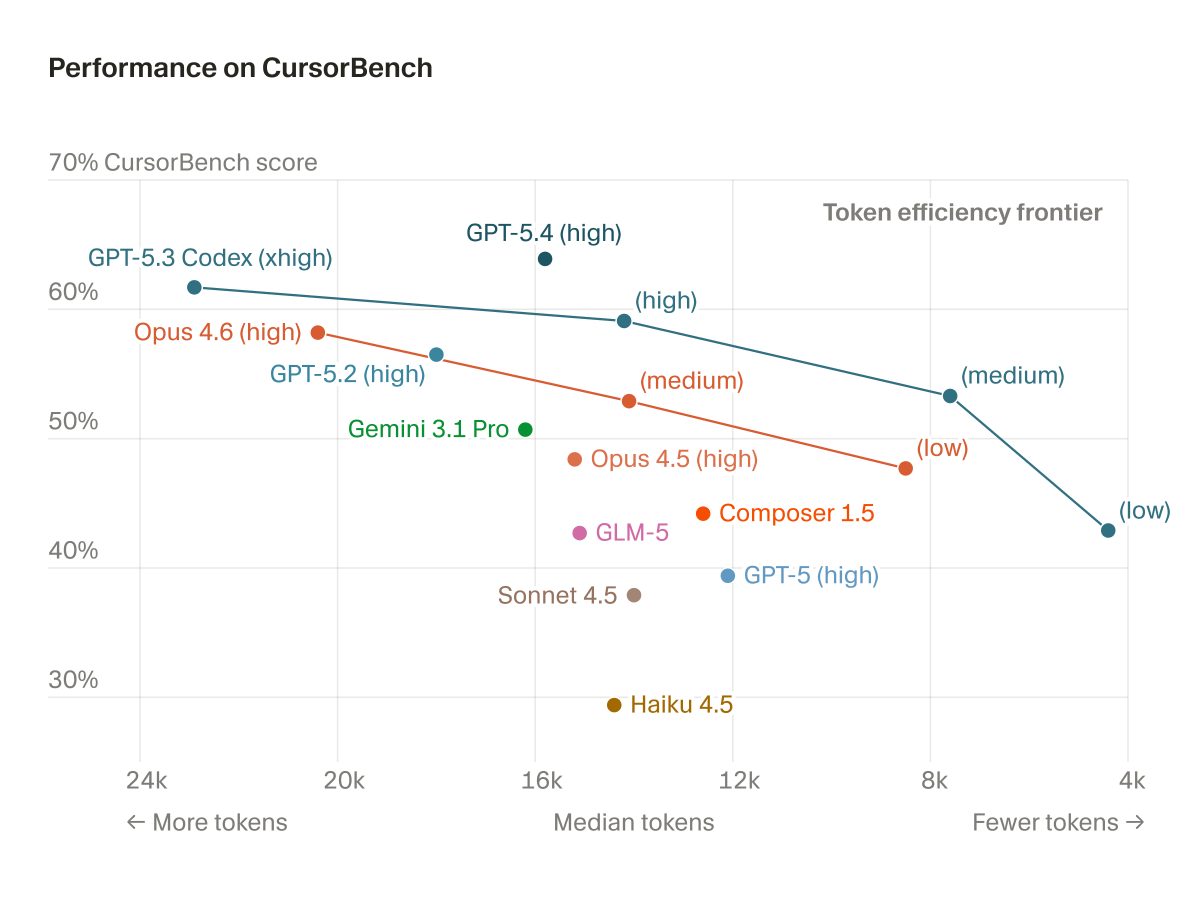
Cursor published a technical report on Composer 2, a coding agent trained via pretraining on Kimi K2.5 and RL on real engineering tasks. It scores 61.3 on CursorBench — 37% above Composer 1.5 — matching frontier models at lower cost.
Kimi K2.5 — a 1.04T parameter, 32B active MoE model — followed by RL on real engineering tasks run in the same harness and environments used in production.Domain-specialized training reaches frontier coding performance at lower inference cost. Composer 2 scores 61.3 on CursorBench — 37% above Composer 1.5 and 70% above base Kimi K2.5 — plus 73.7 on SWE-bench Multilingual and 61.7 on Terminal-Bench, competitive with Opus 4.6 High, at a cost-per-task comparable to smaller variants.
CursorBench tasks have a median of 181 lines changed versus 7–10 for SWE-bench Verified — built from real engineering sessions rather than curated bug fixes. If you follow coding agent development, the benchmark design choices here are as informative as the scores.
We're releasing a technical report describing how Composer 2 was trained. https://t.co/cfW8lyMWEy
Every HeadsUpAI update is written based on its original source and reviewed before it's published. Read our editorial standards →
More like this