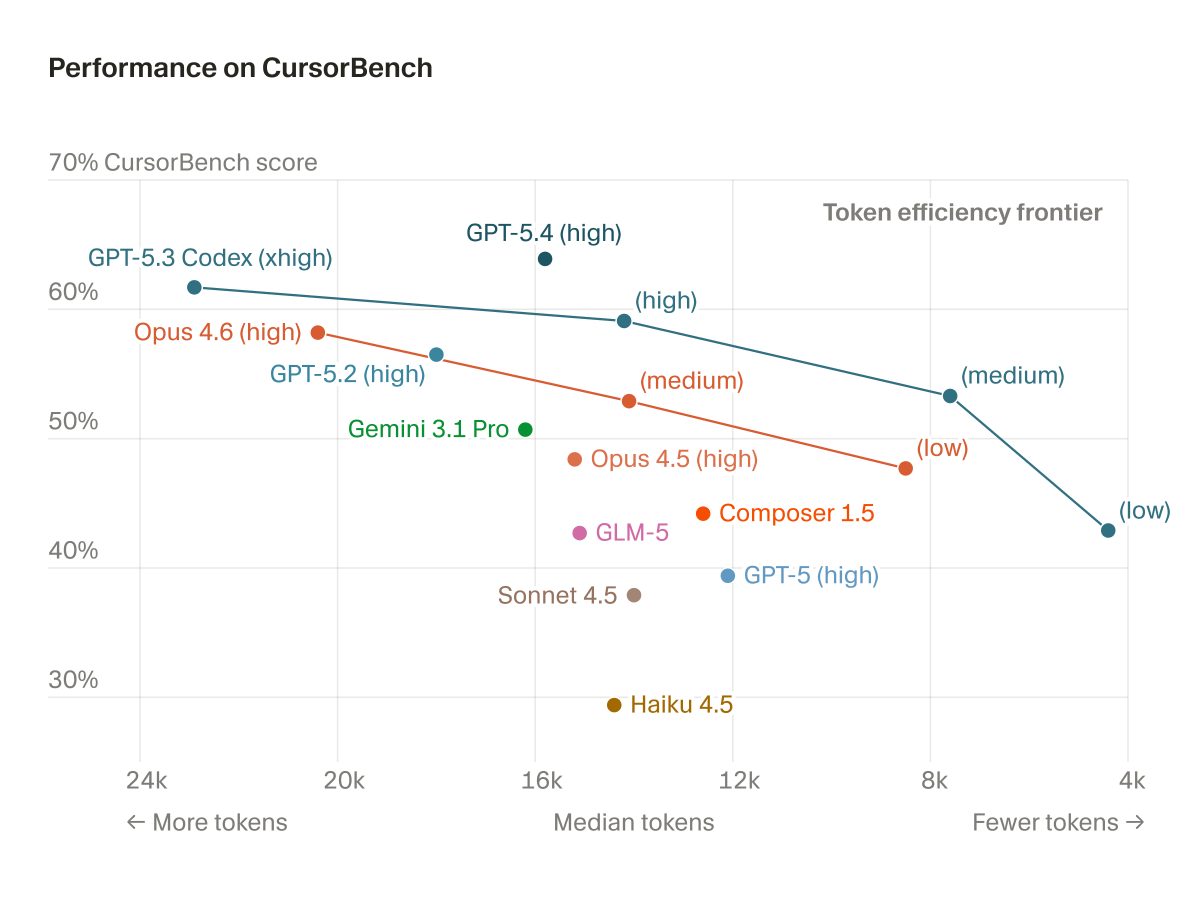
Cursor trained Composer, its agentic coding model, to self-summarize through reinforcement learning rather than prompt-based compaction. This cuts context compaction error by 50% while using one-fifth the tokens, letting Composer handle tasks requiring hundreds of turns.
Cursor trained Composer — its agentic coding model — to self-summarize through reinforcement learning. When Composer hits its context-length trigger mid-task, it pauses, generates a ~1,000-token summary, and continues. The RL loop includes this compaction step so the reward covers both agent responses and each self-summary's quality. On CursorBench Hard (40k and 80k triggers), self-summarization cuts compaction error by 50% versus a tuned prompt-based baseline while using one-fifth the tokens.
Standard compaction — prompted summarization or sliding windows — drops critical information as tasks grow longer. Training summarization as a native behavior means Composer carries task state more reliably across hundreds of turns. Cursor demonstrated this on Terminal-Bench 2.0, a command-line coding benchmark: Composer ran 170 turns, condensing 100,000+ tokens to 1,000.
Try Composer on long refactors or debugging sessions where agents typically lose context mid-way. Self-summarization targets exactly those multi-turn, high-token tasks where standard compaction falls short.