Cognition launched FrontierCode, a new benchmark for evaluating AI-generated code quality and mergeability. This evaluation moves beyond basic functional correctness to assess if AI code meets production standards, addressing the challenge of models producing functional but unmaintainable code.
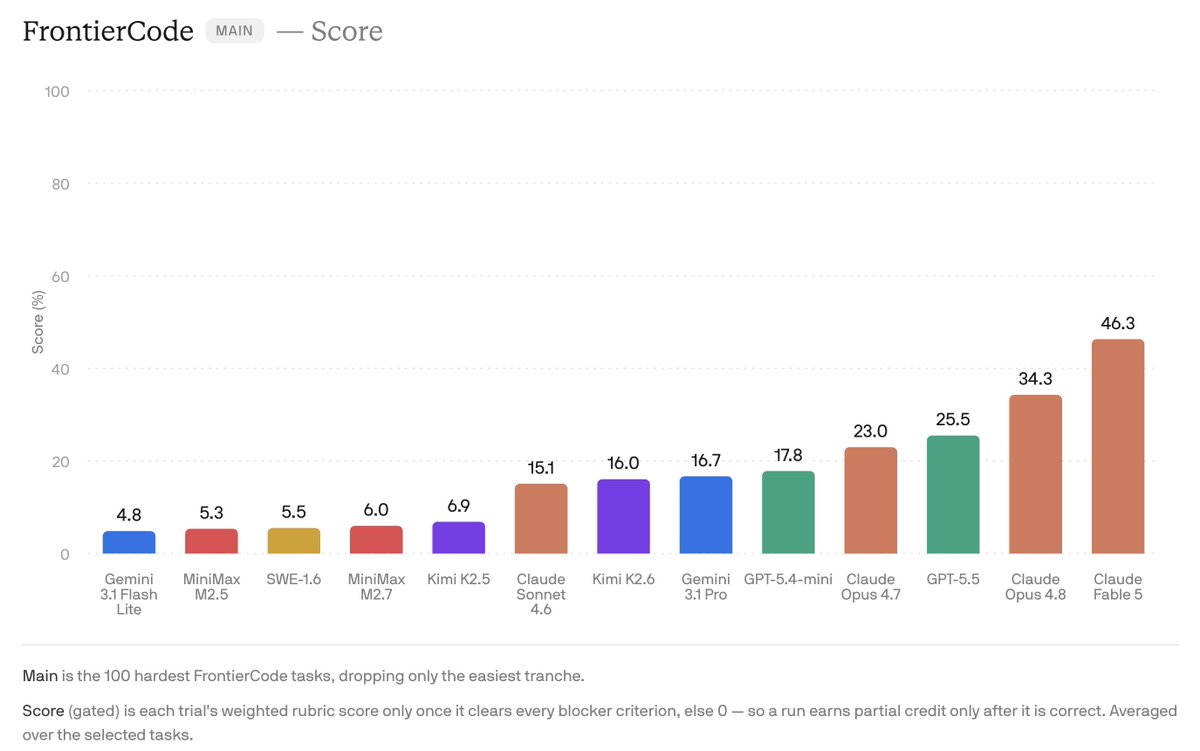
Cognition has introduced FrontierCode, a new coding evaluation benchmark designed to measure the quality and "mergeability" of AI-generated code. Unlike previous benchmarks that primarily focused on functional correctness, FrontierCode assesses end-to-end code quality, including test quality, scope discipline, style, and adherence to codebase standards. Over 20 open-source maintainers crafted each task, investing more than 40 hours per task to ensure real-world relevance.
- Tasks crafted by
- 20+ open-source maintainers
- Effort per task
- 40+ hours
- Misclassification errors
- 81% lower than SWE-Bench Pro
- Task sets
- Extended (150 tasks), Main (100 tasks), Diamond (50 tasks)
- Top model on Diamond
- Claude Opus 4.8 (13.4%)
- Top open-source model on Diamond
- Kimi K2.6 (3.8%)
This benchmark addresses the issue of AI models producing code that, while functional, is often considered sloppy and unmaintainable. FrontierCode employs a mix of unit tests, rubrics, and novel verifiers to provide a more accurate assessment, achieving 81% fewer misclassification errors compared to SWE-Bench Pro. This rigorous quality control helps differentiate models based on their ability to produce high-quality, production-ready code.
FrontierCode offers three task sets: Extended (150 tasks), Main (100 tasks), and Diamond (50 tasks). Initial results show that even frontier models have significant room for improvement, with Claude Opus 4.8 achieving the highest score of 13.4% on the Diamond task set. Cognition is opening its evaluation to all model creators, aiming to push the capabilities of coding agents further.