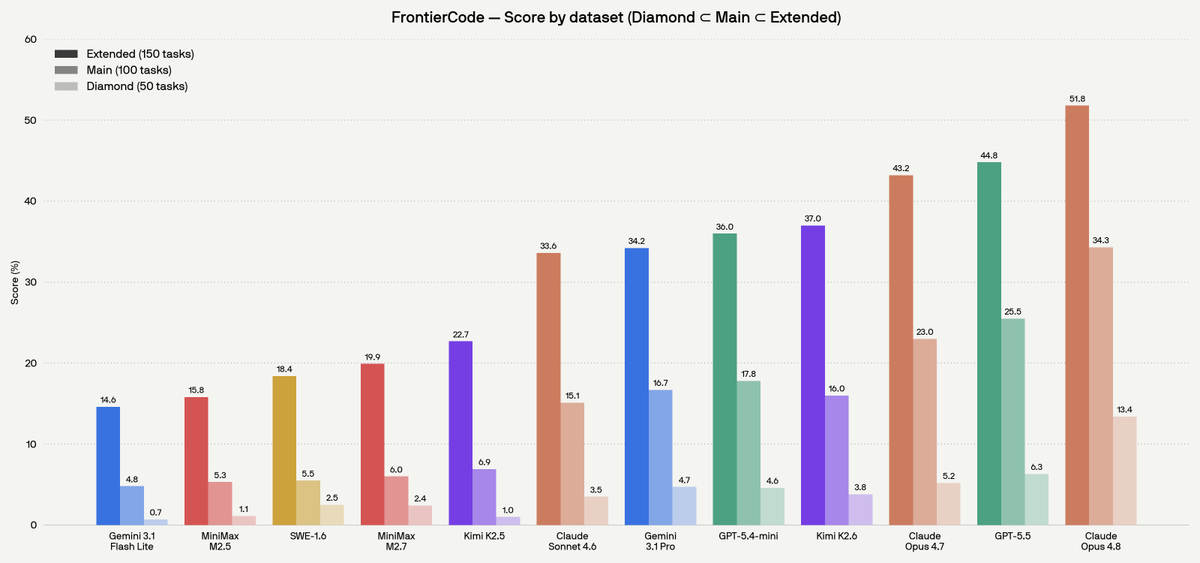
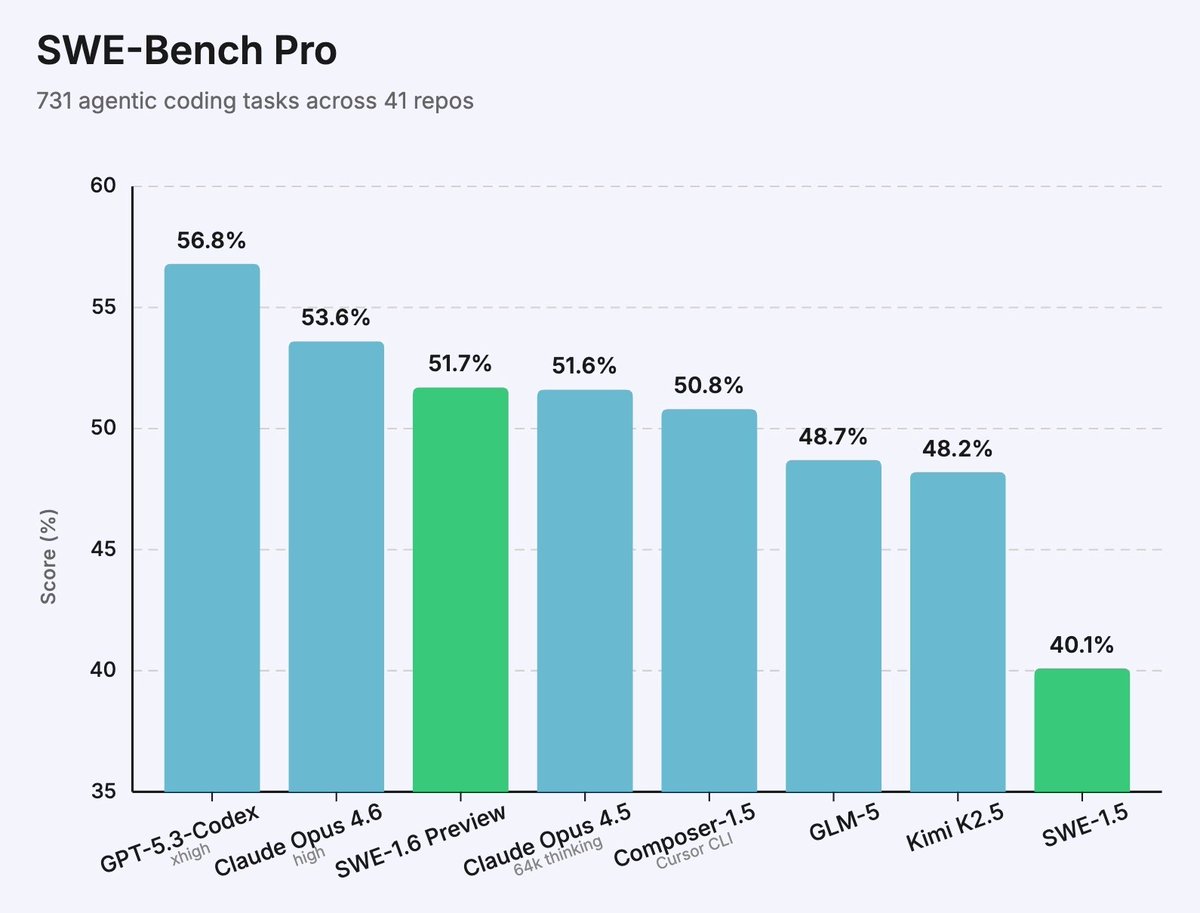
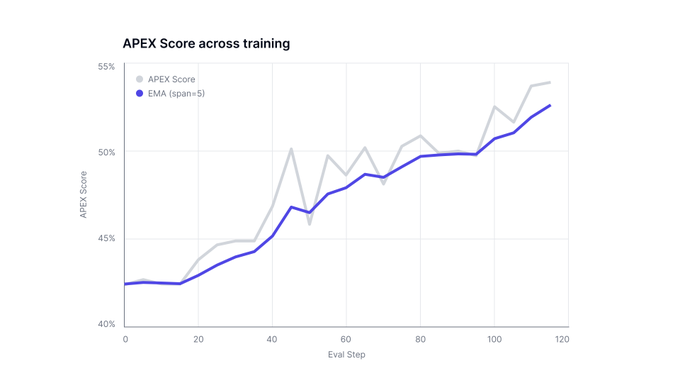
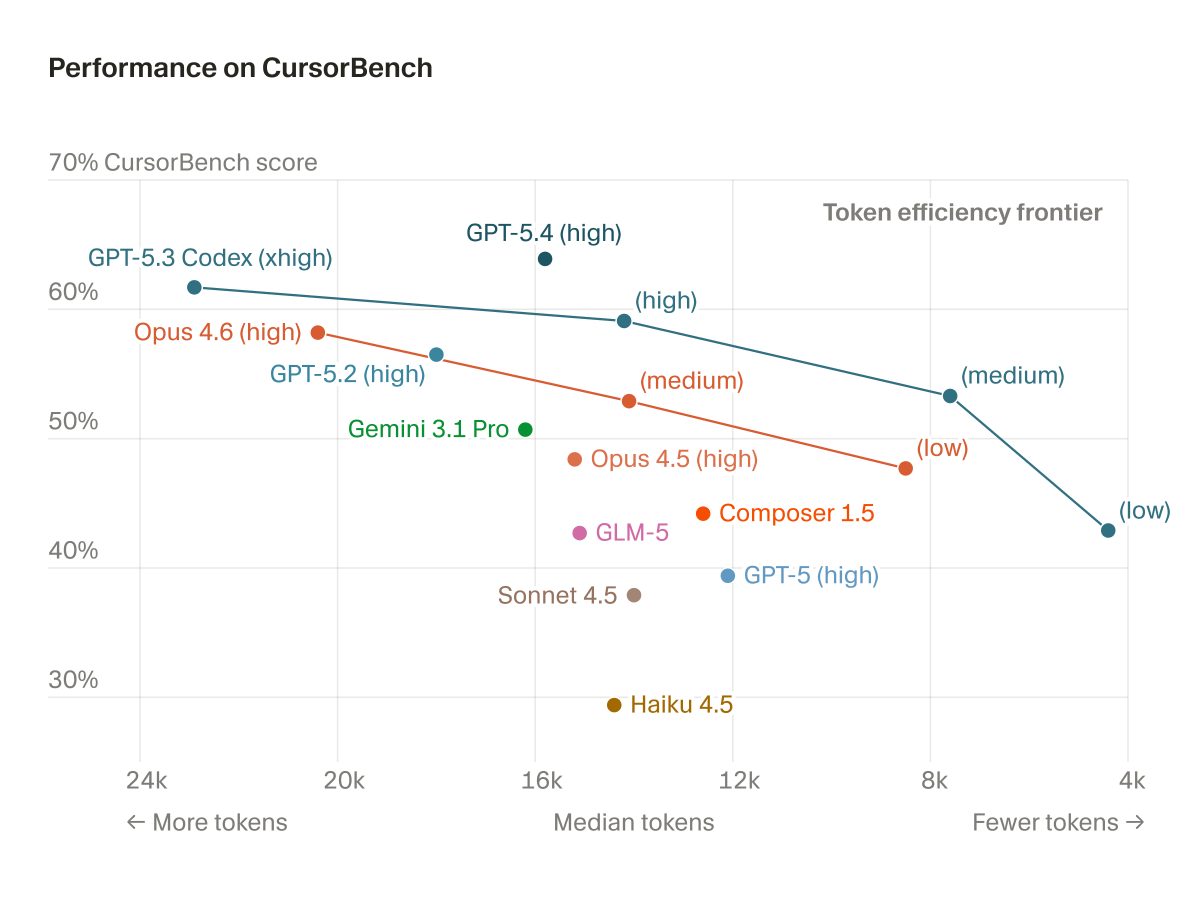
Mercor and Cognition launched APEX-SWE, a benchmark testing AI models on real software engineering — system integration, debugging production failures — not just writing code. Traditional benchmarks miss 84% of dev work. Even the top model scores just 41.5%.
APEX-SWE, built by Mercor and Cognition, tests whether AI models can handle real production software engineering. It covers integration tasks (building systems across cloud services and business APIs) and observability tasks (diagnosing production failures from logs). GPT-5.3 Codex leads the launch leaderboard at 41.5% Pass@1; every model fails over half the tasks.
Traditional coding benchmarks have become saturated, presenting a misleading picture of AI coding ability — developers spend only 16% of their time writing code, per IDC. The remaining 84% is deployment, monitoring, and debugging: exactly what APEX-SWE measures. Models that top 75% on SWE-bench Verified drop to under 42% here.
If you're deciding how much to trust AI agents for production engineering — not just code writing — APEX-SWE gives you the number that matters. The eval harness and a 50-task dev set are open-source on GitHub and Hugging Face for anyone testing models against real work.