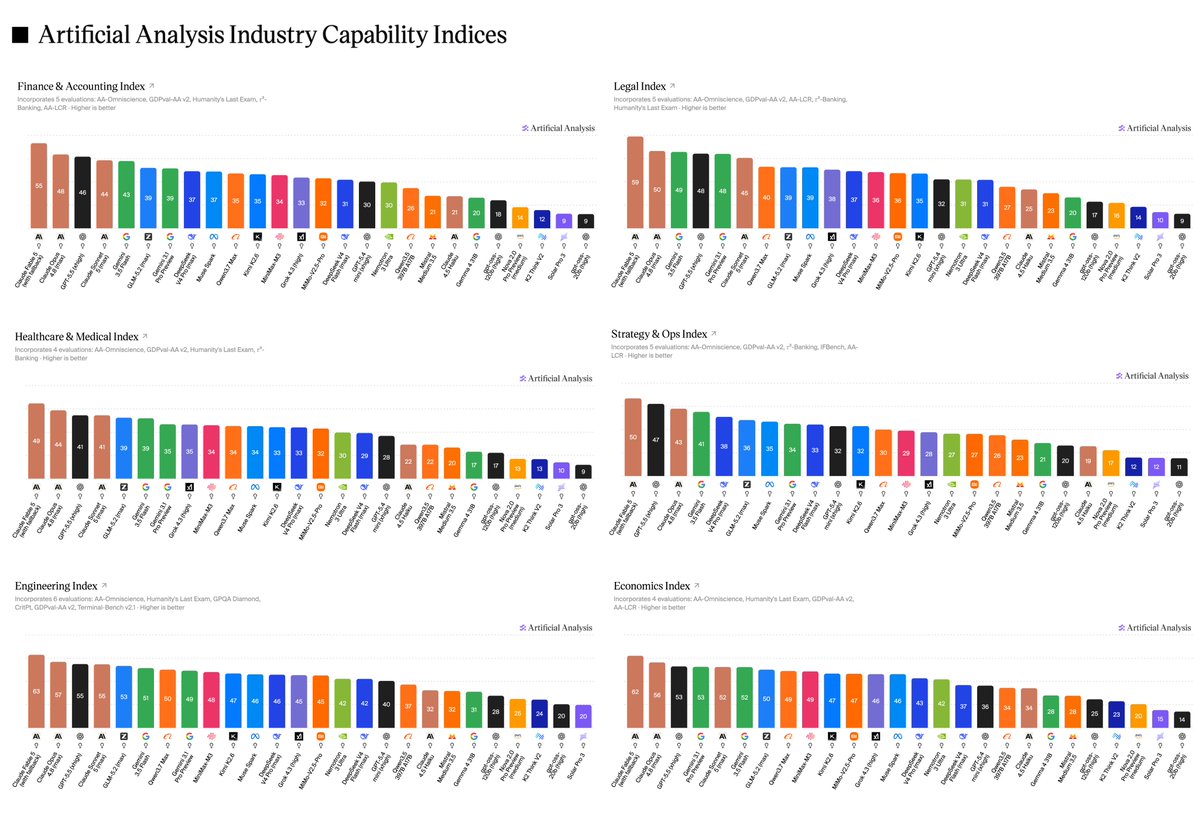
Artificial Analysis and IBM Research launched ITBench-AA, a benchmark evaluating AI agents on autonomous Kubernetes incident diagnosis. The results show that even frontier models struggle with complex IT troubleshooting, with the highest-performing models currently scoring below 50%.
Artificial Analysis, an independent AI benchmarking firm, partnered with IBM to launch ITBench-AA, a series of evaluations for agentic enterprise IT tasks. Using the Stirrup agent harness, they found that every frontier model currently scores below 50% when identifying root-cause entities from Kubernetes incident snapshots.
- Top score (Claude Opus 4.7)
- 46.7%
- Second score (GPT-5.5 xhigh)
- 45.8%
- Lowest cost per task
- $0.14 (Gemma 4 31B Reasoning)
- Highest cost per task
- $5.38 (Claude Opus 4.7)
- Task count
- 59 Kubernetes incidents
The benchmark reveals a performance gap in autonomous IT operations and highlights a disconnect between verbosity and accuracy. Models taking more turns often underperform concise ones, validating Fireworks AI's execution tax analysis, which found that reliability in multi-step loops is more critical than raw intelligence for maintaining agentic cost efficiency.
Claude Opus 4.7 (Max Effort) leads the leaderboard at 46.7%, followed by GPT-5.5 (xhigh). While frontier models lead on accuracy, smaller models like Gemma 4 31B (Reasoning) offer better cost efficiency. You can access the leaderboard and dataset to test your own agents on these Site Reliability Engineering tasks.