Arena.ai
@arena
Grok 4.3 by @xAI is in Battle Mode in the Text, Vision, Document & Code Arena: Front-end. Come test it out with your toughest prompts. Scores coming soon! https://t.co/6gWt5Ba87d
17retweets301likes
View on X· Updated
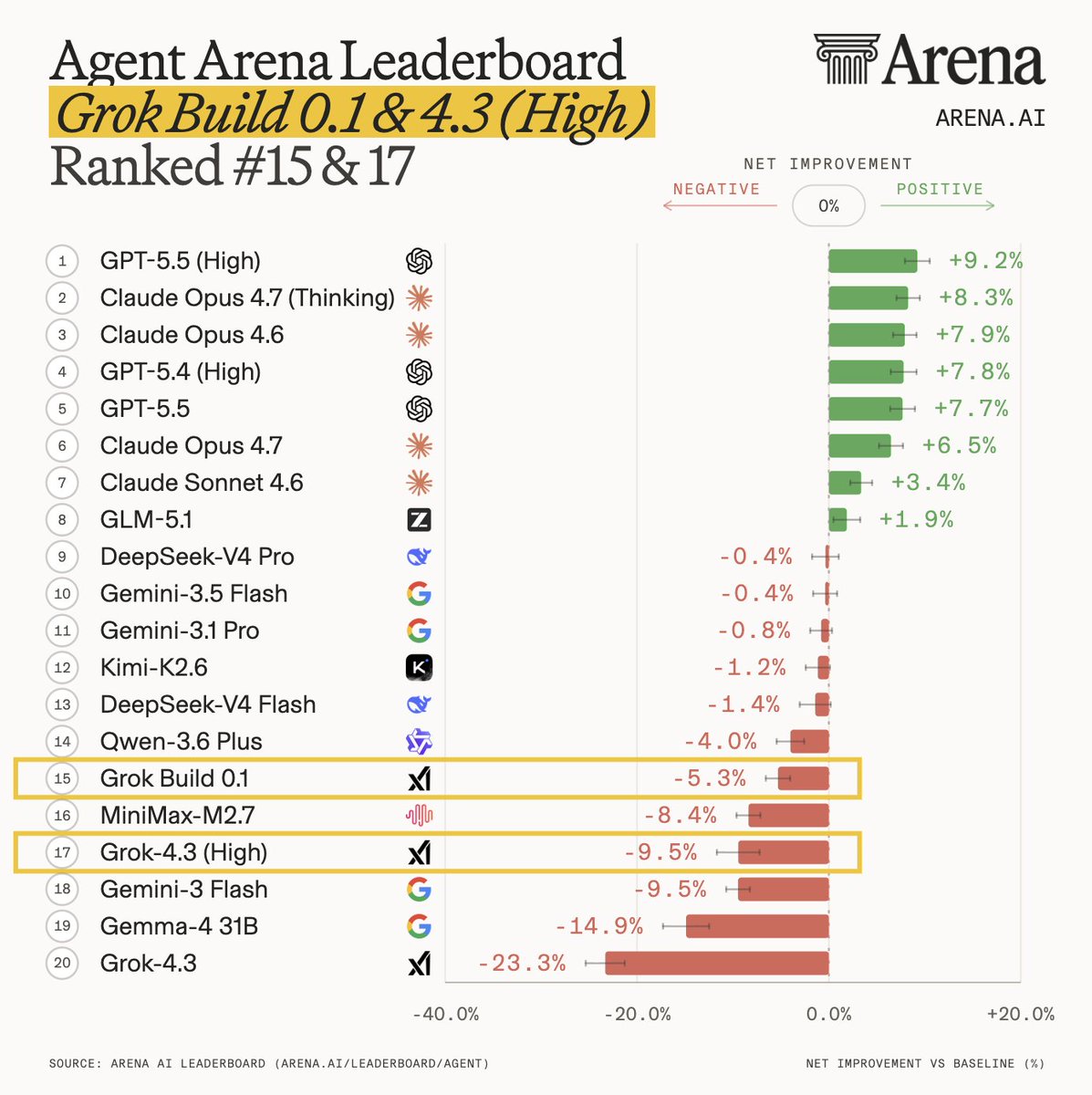
Arena.ai added xAI's Grok 4.3 to its blind evaluation leaderboards for text, vision, documents, and frontend coding. This move subjects the new reasoning model to real-world human preference testing to verify its performance against established frontier models.
This entry follows recent additions like GPT-5.5's top-tier ranking and Tencent's Hy3 preview. By entering the Arena, Grok 4.3 moves beyond static benchmarks to face blind human preference testing. This process provides a verified Elo rating (a relative skill ranking system) that is harder to game than static datasets.
You can now test Grok 4.3's reasoning and multimodal capabilities by submitting prompts to the Arena's blind battle interface. While official leaderboard scores are pending, the platform is currently collecting the community votes required to rank the model against DeepSeek V4 Pro and other top-performing systems.
Grok 4.3 by @xAI is in Battle Mode in the Text, Vision, Document & Code Arena: Front-end. Come test it out with your toughest prompts. Scores coming soon! https://t.co/6gWt5Ba87d
Still wondering? A few quick answers below.
Every HeadsUpAI update is written based on its original source and reviewed before it's published. Read our editorial standards →