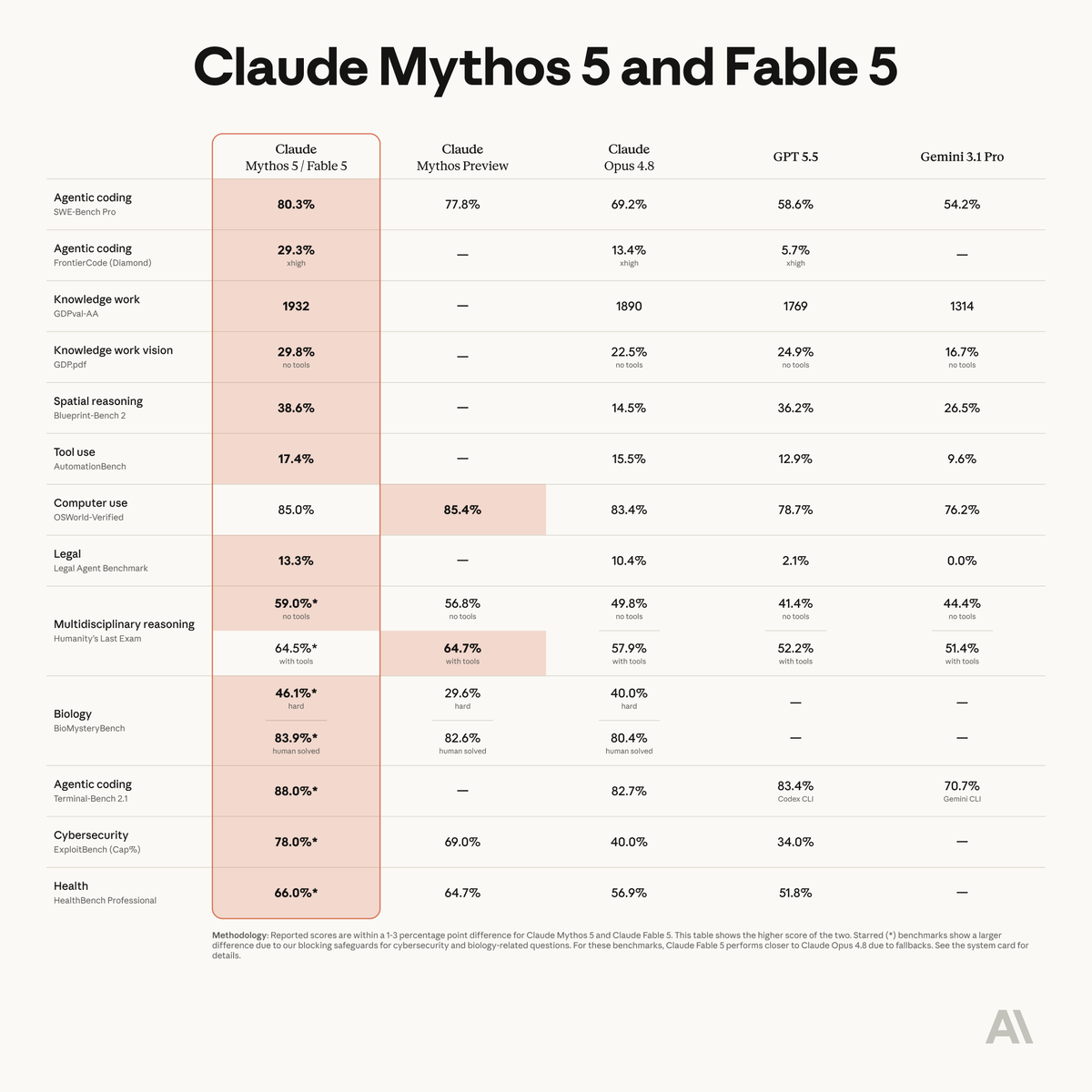
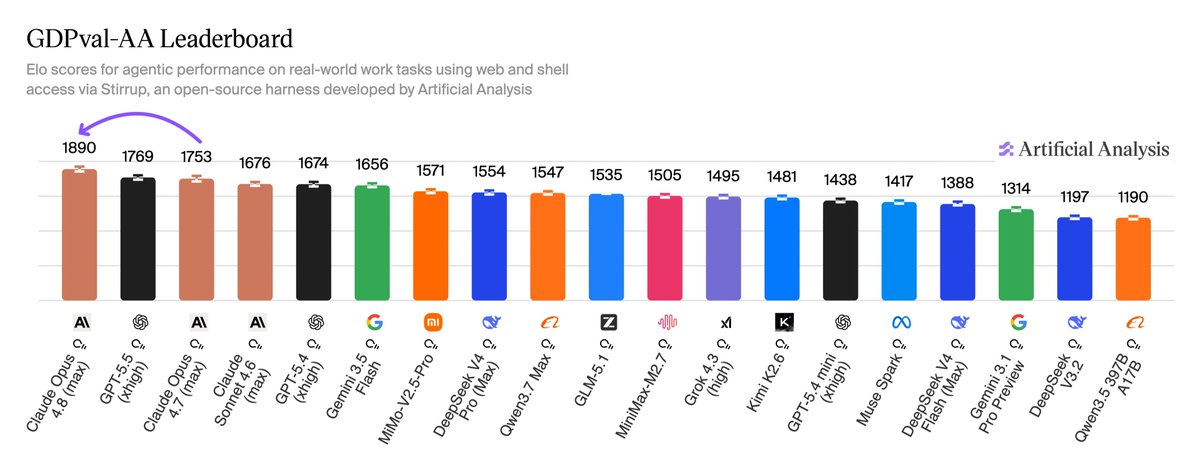
Anthropic has released Claude Fable 5, the first publicly available Mythos-class model that ranks #1 in our agentic real-world knowledge work benchmark GDPval-AA Claude Fable 5 shares the same underlying model as Claude Mythos 5, with added security guardrails for potentially harmful cybersecurity, biology, chemistry, and distillation-related queries. The release also introduces a fallback mechanism, allowing Claude Fable 5 to route flagged queries to a second model such as Claude Opus 4.8. @AnthropicAI shared access with us ahead of public release to benchmark this model. Claude Fable 5 scores 1932 on GDPval-AA, our benchmark for agentic real-world work tasks, taking the #1 position and putting Anthropic models in 3 of the top 4 spots. The result was measured using adaptive reasoning at max effort, with Claude Opus 4.8 configured as the fallback model. Fable 5 falls back to Opus 4.8 on 2% of GDPval-AA tasks, with Anthropic stating that fallback occurs in fewer than 5% of sessions on average. Full benchmarks for Claude Fable 5 are in progress - we will share the full Intelligence Index and publish scores on our website shortly
Anthropic Releases Claude Fable 5, Tops Agentic Work Benchmark with Safeguards
· Updated
Anthropic has released Claude Fable 5, its first publicly available Mythos-class model, which ranks #1 on Artificial Analysis's GDPval-AA benchmark. This model includes new security guardrails for high-risk domains and a fallback mechanism to Claude Opus 4.8, setting a new standard for capable and responsibly scaled AI.
- GDPval-AA Rank
- #1
- GDPval-AA Score
- 1932
- Fallback Model
- Claude Opus 4.8
- Fallback Rate (GDPval-AA)
- 2%
- Model Class
- Mythos-class
- Underlying Model
- Claude Mythos 5
Claude Fable 5 achieved the #1 position on Artificial Analysis's GDPval-AA benchmark, scoring 1932 for agentic real-world knowledge tasks. This performance surpasses previous leaders like Claude Opus 4.8 (1890 Elo) and GPT-5.5, highlighting its advanced capabilities.
Claude Fable 5 is available for general access, offering advanced agentic capabilities. Its integrated safeguards, including fallback to Claude Opus 4.8 on 2% of GDPval-AA tasks, ensure responsible deployment. This approach provides a powerful tool, aligning with principles outlined in Claude's constitution.
Every HeadsUpAI update is written based on its original source and reviewed before it's published. Read our editorial standards →