Alibaba Releases Qwen3.7-Plus to Automate Software Tasks via Unified Vision and Code
Qwen·
· Updated
Alibaba released Qwen3.7-Plus, a multimodal foundation model that integrates vision and language reasoning into a single agent loop. The update enables AI agents to perceive graphical interfaces and execute command-line operations to automate complex software development and productivity workflows.
Alibaba released Qwen3.7-Plus, a multimodal foundation model (a large AI model trained on broad data) designed as a unified agent for visual and textual tasks. Building on the Qwen3.7 text backbone, it upgrades vision-language capabilities to perceive scenes, read screens, and execute actions across graphical and command-line interfaces.
Context Window
1,000,000 tokens
Max Output Tokens
65,536
Input Modalities
Text, Image, Video
Framework Support
Claude Code, OpenClaw, Qwen Code
Benchmark Performance
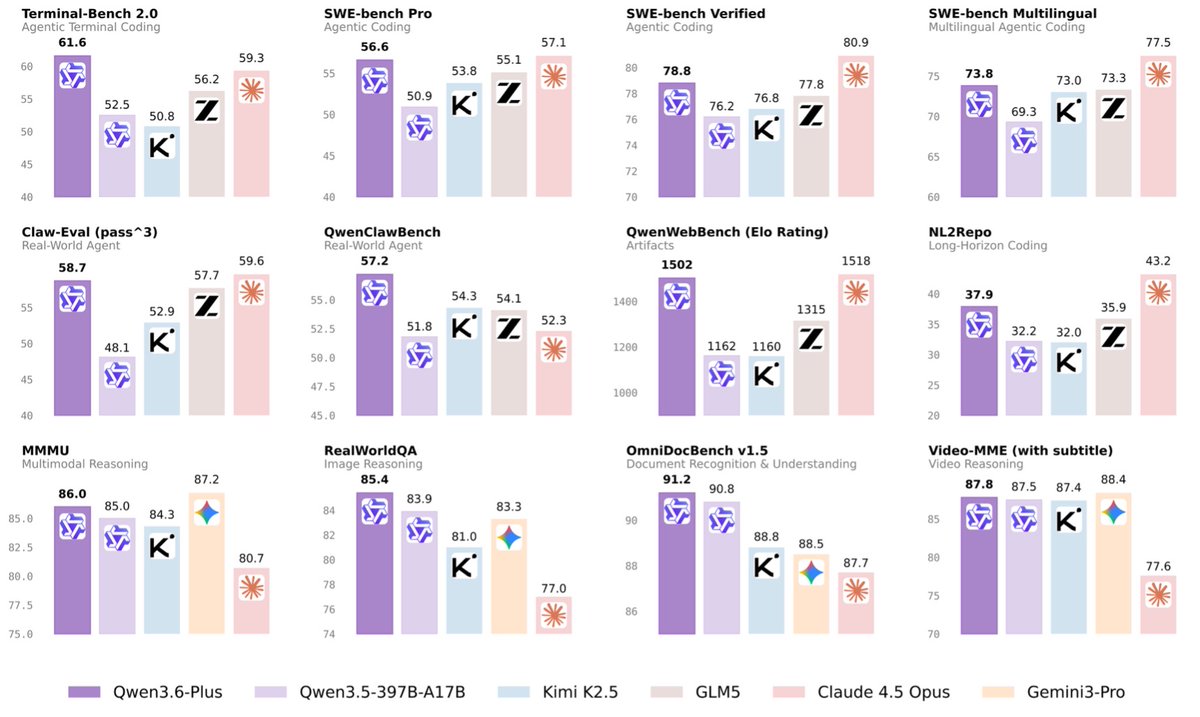
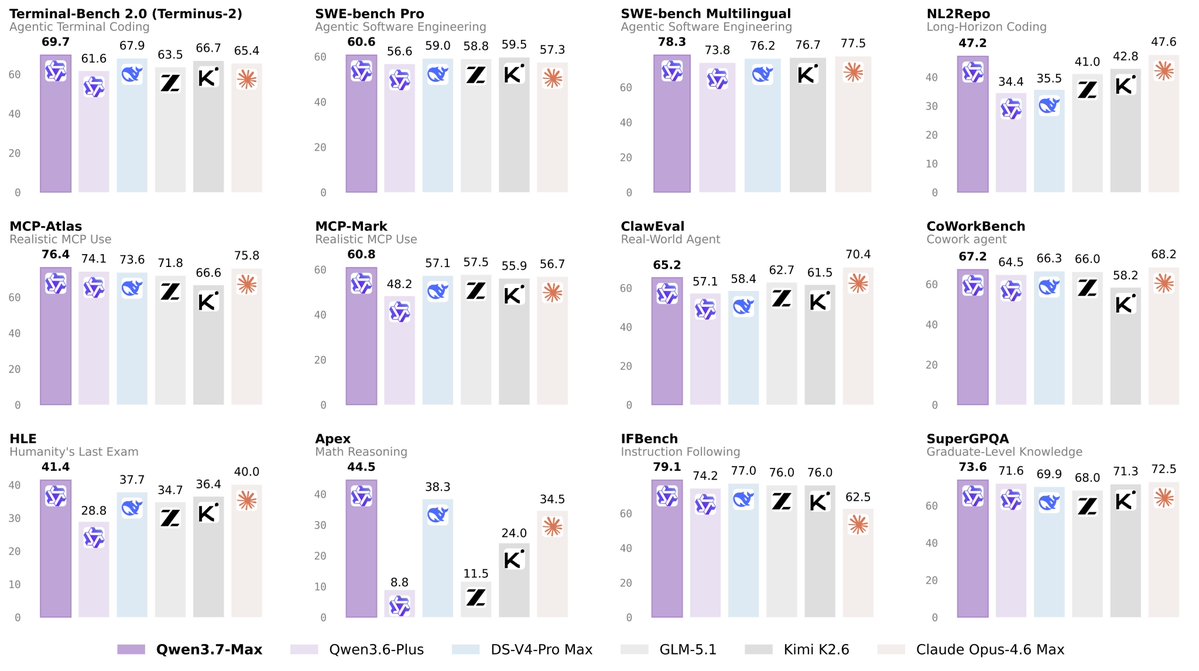
70.3 on Terminal Bench 2.0
This release makes vision a core component of the agent's reasoning loop. While Qwen3.6-Plus focused on autonomous workflows, qwen3.7-plus demonstrates higher generalization across frameworks. It competes with models like GLM-5V-Turbo by enabling agents to actively build and operate interfaces rather than just understanding them.
Users can access qwen3.7-plus via the Alibaba Cloud Model Studio API, which supports preserve_thinking for multi-turn tasks. The model integrates with Claude Code, OpenClaw, and Qwen Code to automate workflows from frontend prototyping to complex software engineering and multi-step workflow automation.
👏👏 Introducing Qwen3.7-Plus — a multimodal agent model that unifies vision and language into one versatile agent foundation.
✅ Multimodal interactive hybrid agent: unified GUI & CLI operation across visual and text tasks
✅ Versatile coding agent & productivity assistant with full-modality input
✅ Visual Agent: perception, reasoning, grounding, and search-augmented QA
✅ Cross-harness generalization across diverse agent frameworks
One model. Sees, thinks, codes, acts.🙌🙌
Now available via API on Alibaba Cloud Model Studio. Try it — let us know what you build.😎
🔗🔗⬇️⬇️
Blog:https://t.co/pVYf0h3NNa
Qwen Studio:https://t.co/HUYgFW4cYf
API:https://t.co/viL0cXrMzW
Alibaba's Qwen3.7-Plus is a multimodal foundation model designed to act as a unified agent for both visual and textual tasks. It integrates vision and language reasoning into a single loop, allowing it to perceive real-world scenes, read screen content, and execute actions across graphical and command-line interfaces for complex automation.
The model uses its native vision capabilities to perceive graphical user interfaces, identifying UI elements and understanding task intent from visual references. It can then execute multi-step interactions, such as navigating mobile apps or cloud consoles, by blending visual perception with tool use and code generation to complete end-to-end tasks.
Qwen3.7-Plus is available via the Alibaba Cloud Model Studio API, which is compatible with industry-standard OpenAI protocols. It also integrates with popular agentic coding frameworks like Claude Code and OpenClaw, and can be accessed through the Qwen Studio web interface for document processing, web search, and image understanding.
Yes, the model is optimized for agentic coding and productivity workflows. It can transform visual design references into executable code, such as SVG icons or full webpage prototypes. It also performs strongly on coding benchmarks like SWE-bench, handling real-world software engineering tasks and complex GPU kernel optimization.
Every HeadsUpAI update is written based on its original source and reviewed before it's published. Read our editorial standards →