Alibaba Cloud released Qwen3.5-Omni, a native omni-modal foundation model that processes text, images, audio, and video within a single end-to-end architecture. This update introduces real-time interactive capabilities and a new feature called Audio-Visual Vibe Coding.
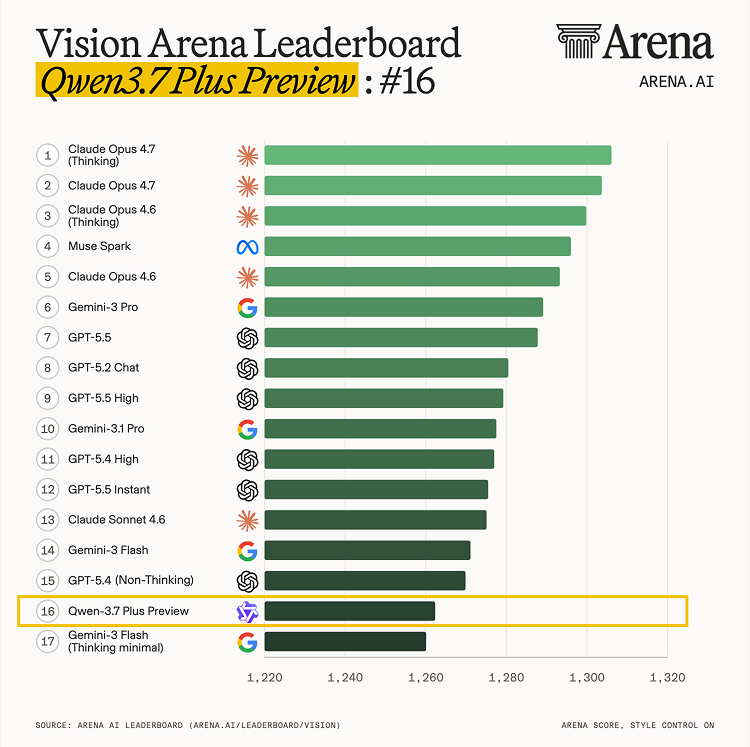
Alibaba Cloud's Tongyi Lab launched Qwen3.5-Omni, the latest generation of its foundation model series. This version is natively omni-modal, meaning it processes text, image, audio, and video inputs through a single, end-to-end architecture. It achieves state-of-the-art performance across all four modalities simultaneously.
The release marks a shift toward real-time, multi-sensory interaction. By integrating audio-visual understanding directly into the core model, Qwen3.5-Omni can perform complex tasks like automatic video segmentation and script generation that accounts for character relationships. It maintains high performance across all modalities while advancing real-time interaction.
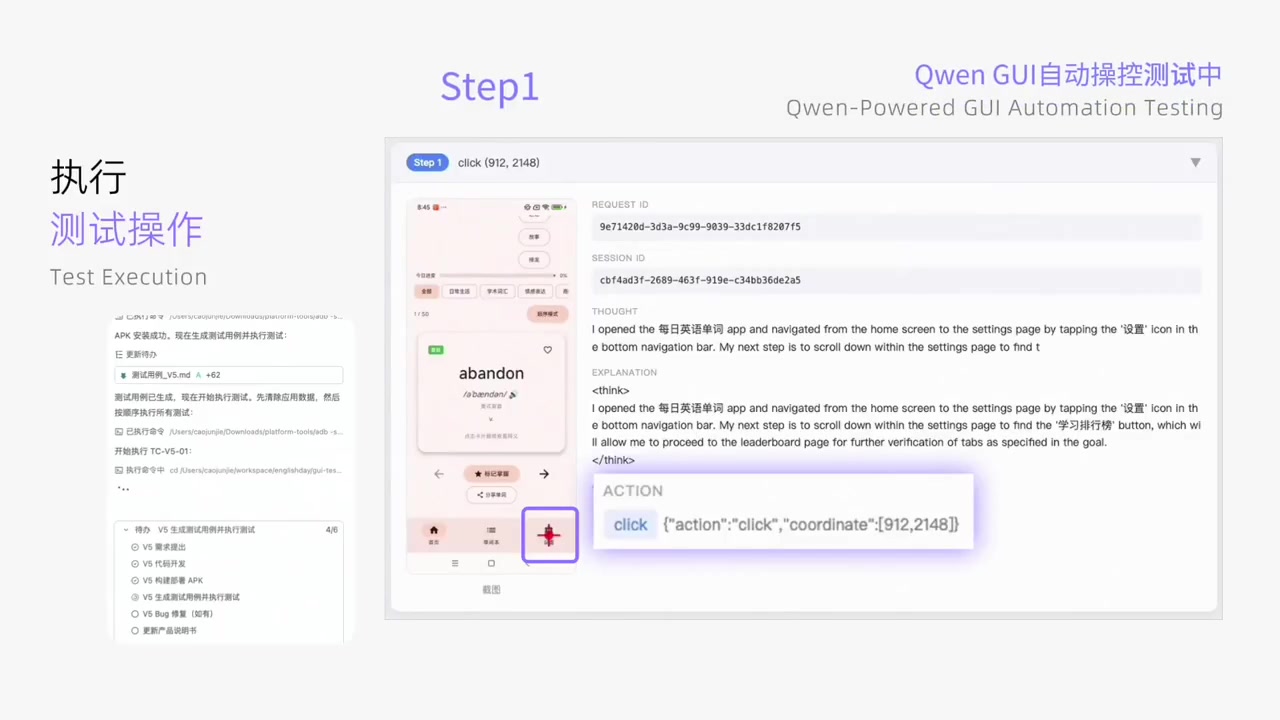
You can now use Qwen3.5-Omni for workflows requiring fine-grained video analysis or real-time conversational agents. The standout Audio-Visual Vibe Coding feature introduces a multi-sensory approach to development. The model is available for online serving via the vLLM Python client, supporting query types for audio and video.