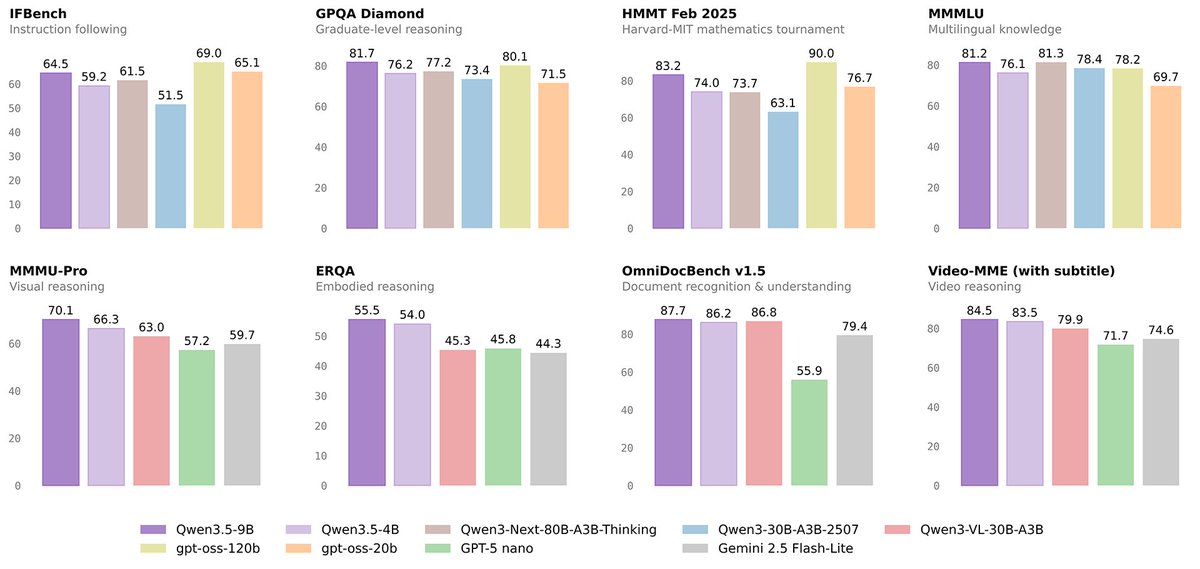
Qwen 3.5 vision models are now available locally via Ollama, with the 35B fitting on a 24GB GPU. All three models include built-in vision, expanded language support, and improved efficiency compared to previous Qwen releases.
Ollama added the Qwen 3.5 family to its local model library. The 35B model (MoE architecture) runs on systems with 24GB+ GPU memory — ollama run qwen3.5:35b. The 122B variant follows for higher-end setups, while the 397B remains cloud-only. All three include vision built-in, replacing the separate VL model variants from Qwen 2.5.
The shift to native vision is significant for local AI workflows - you no longer need a separate vision model or a cloud API to handle images and documents alongside text. Qwen 3.5 also adds broader multilingual support and more efficient inference, making it a direct upgrade path for anyone running Qwen locally.
For 24GB GPU owners, ollama run qwen3.5:35b is the fastest way to try it. The 122B model is available for workstations with more VRAM.