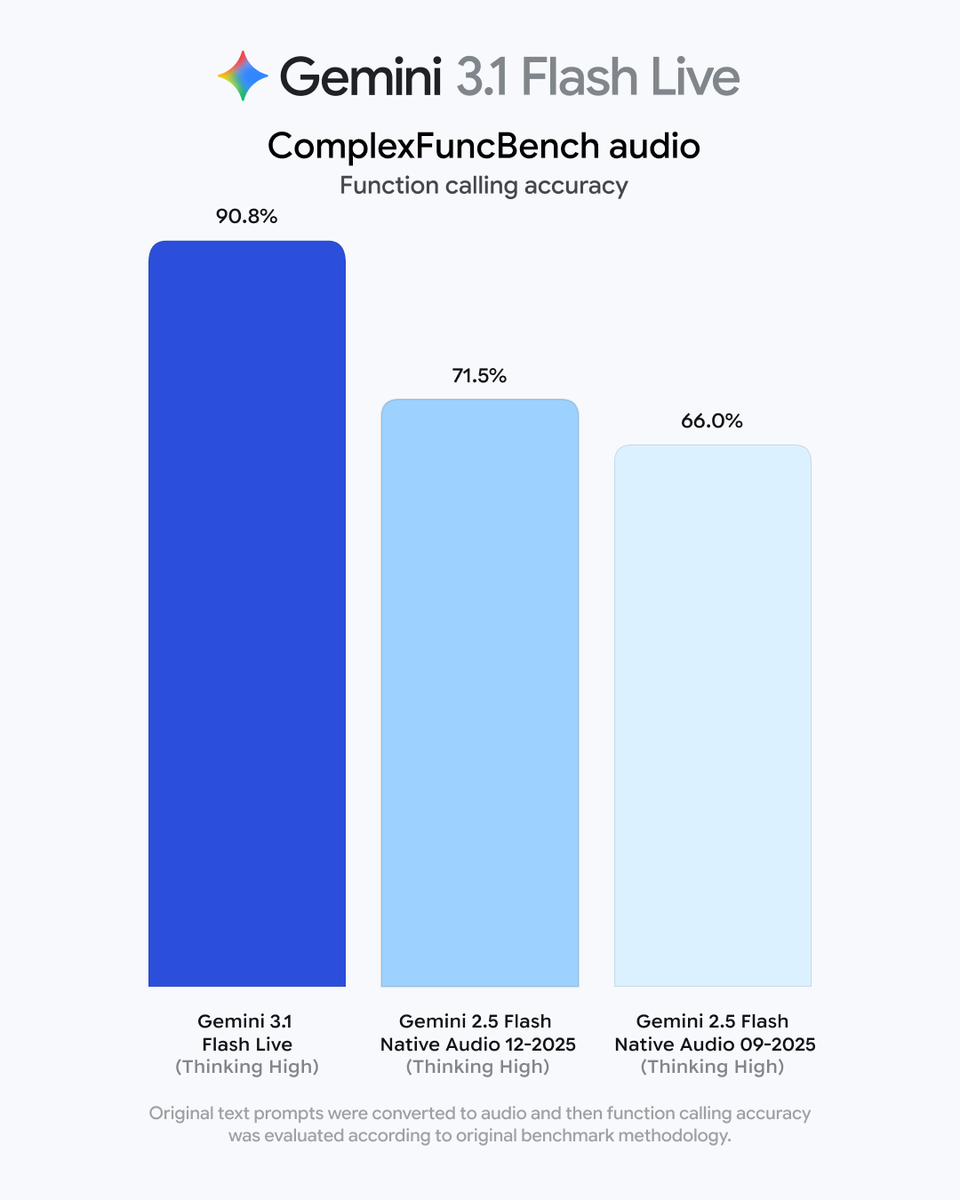
OpenAI published a technical guide for gpt-realtime-2 that introduces granular controls for reasoning effort and spoken preambles. This shift allows developers to tune the balance between voice latency and complex problem-solving for autonomous audio interactions.
OpenAI released a technical guide for gpt-realtime-2, its reasoning voice model for low-latency speech-to-speech applications. It introduces a reasoning.effort parameter (controls internal processing time before responding) with levels from minimal to high. This allows developers to trade speed for deeper logic.
- Reasoning effort levels
- minimal, low, medium, high
- Context window
- 128K tokens
- Response phases
- commentary, final_answer
- Preamble length
- One to two sentences
- Availability
- OpenAI API
This update shifts voice AI from simple conversational loops to reasoning-capable agents that can plan multi-step actions. By formalizing preambles—short spoken updates that fill silence during reasoning—OpenAI addresses voice latency. It builds on the gpt-realtime-2 launch to provide engineering patterns for reliable, high-precision audio interfaces.
You can now implement entity capture workflows that use digit-by-digit confirmation for high-precision data like order IDs. The model also supports an expanded 128k token context window (the amount of information a model can process at once), enabling sessions lasting up to two hours. These capabilities are available via the OpenAI API.