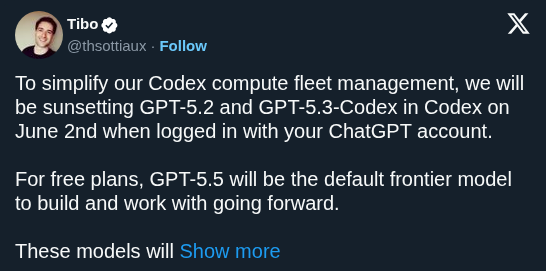
Tibo, the Codex engineering lead at OpenAI, clarified that each decimal increment in the GPT-5 series represents simultaneous gains in model capability and token efficiency. This strategy ensures that newer versions like GPT-5.5 deliver higher intelligence without the speed penalties typically associated with larger models.
OpenAI engineering lead Tibo explained the company's versioning philosophy for the GPT-5.0 through GPT-5.5 series. Each decimal increment signals a dual improvement: a step up in raw model capabilities and a corresponding increase in token efficiency. This convention ensures that version bumps translate directly to faster real-world performance.
- Versioning logic
- Decimal increments signal capability and efficiency
- Efficiency impact
- Higher token efficiency translates to speed gains
- Strategy status
- OpenAI plans to continue this numbering convention
- Source authority
- Tibo, Codex engineering lead at OpenAI
- Validation metric
- GPT-5.5 reached 82.7 percent on Terminal-Bench 2.0
This clarification provides a framework for interpreting the rapid release cycle of the GPT-5 family. The strategy was recently demonstrated by GPT-5.5, which achieved state-of-the-art results while requiring significantly fewer tokens than its predecessors. This efficiency gain was a core finding in OpenRouter's GPT-5.5 cost analysis, which noted that conciseness partially offsets higher pricing.
OpenAI intends to continue this incremental strategy for future releases. By tying version numbers to efficiency, the company aims to maintain the agentic performance gains established during the OpenAI GPT-5.3-Codex launch while keeping latency low. Future versions like GPT-5.6 should follow this same pattern of simultaneous intelligence and speed upgrades.