NVIDIA AI
@NVIDIAAI
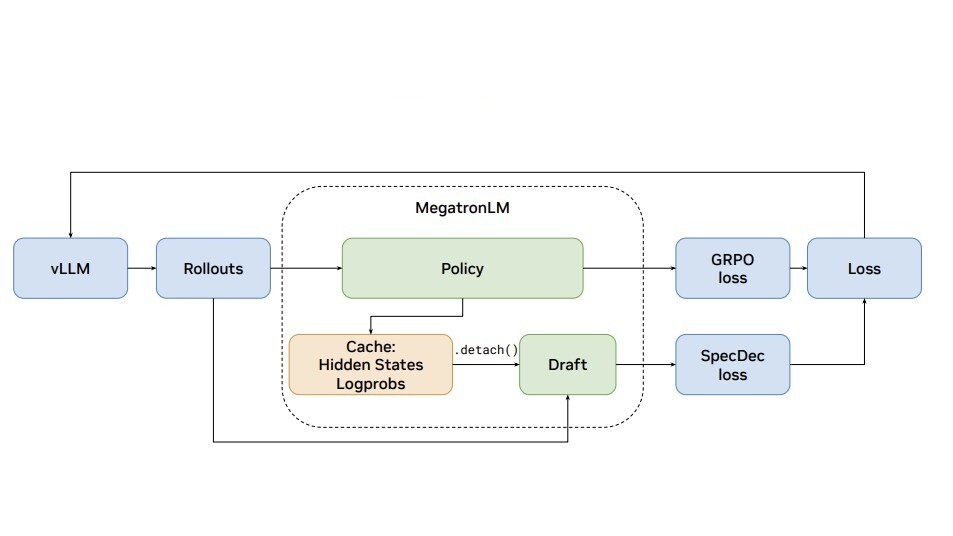
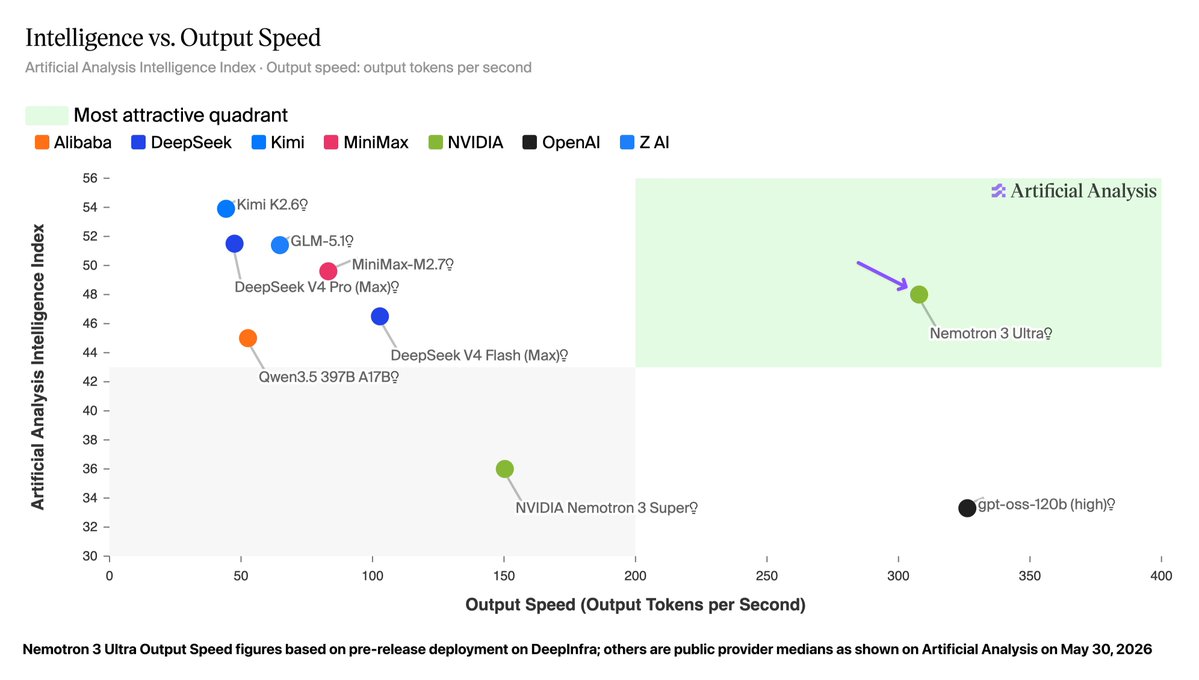
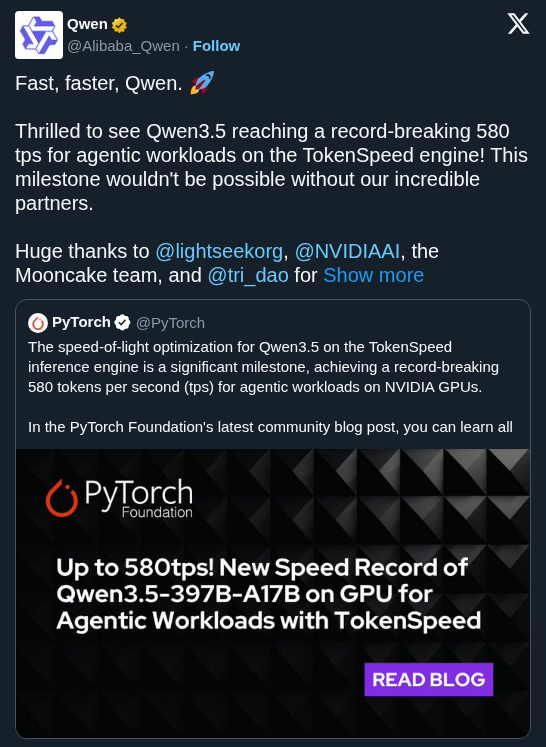
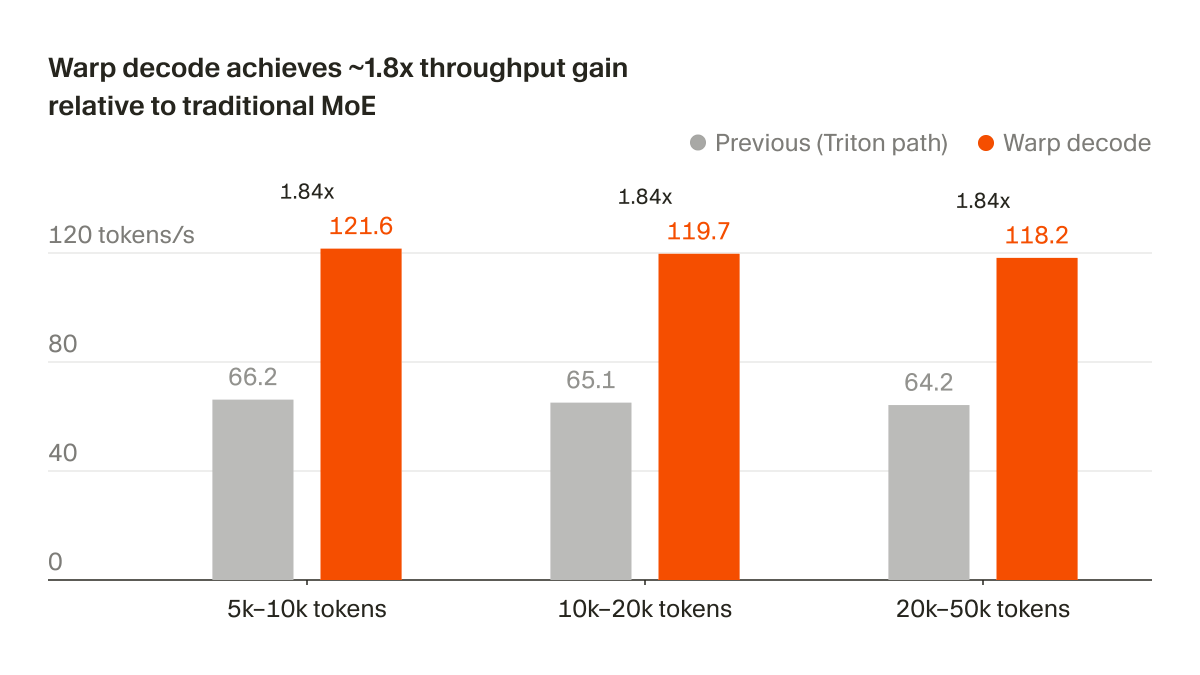
Training Kimi K2 and Qwen3 30B-scale models efficiently requires more than standard data-parallel tricks. NVIDIA Megatron Core now provides end-to-end support for emerging higher-order optimizers like Muon, alongside research optimizers such as MOP and REKLS, to push training efficiency on GB300 GPUs and NVL72 systems. Full breakdown 👇 https://t.co/D7E55OnCiK
18retweets125likes
View on X