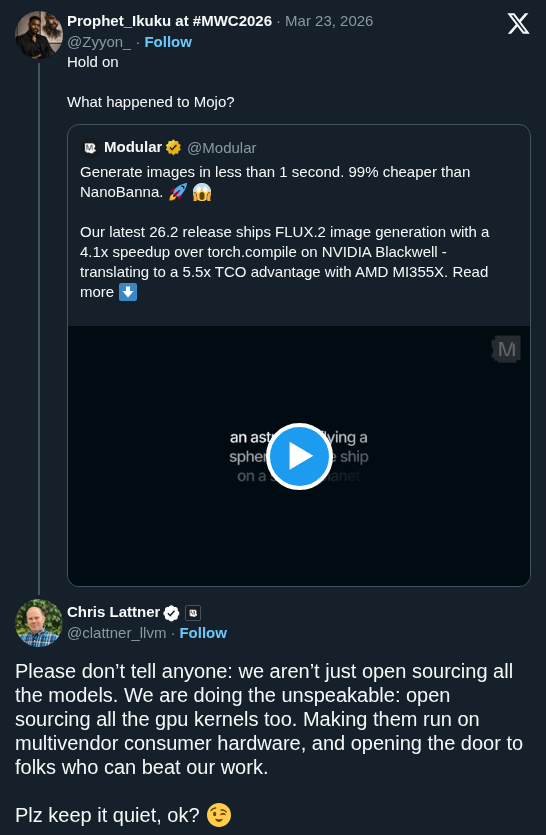
Modular released version 26.2 with Mojo coding agent skills purpose-built for GPU kernel development, enabling coding agents to translate CUDA kernels to idiomatic Mojo. The update also brings FLUX.2 image generation via MAX at 3.4–4.1x faster than PyTorch Diffusers.
Modular, an AI infrastructure platform, released version 26.2 with Mojo coding agent skills that plug into Claude, Cursor, and Codex. Point an agent at a CUDA or Triton kernel and the skill handles structural translation to idiomatic Mojo. The release also adds FLUX.2 image generation via MAX at 3.4–4.1x speedup over PyTorch Diffusers with up to 5.5x TCO savings on AMD MI355X.
Mojo's Python-like syntax, strong type safety, and compile-time error catching shorten debug cycles for agent-generated GPU code. The skills enforce idiomatic patterns and correct outdated code, backed by over 750K lines of open-source Mojo kernel implementations that give agents a large reference base for writing portable kernels.
Teams running GPU workloads in CUDA can use the new skills to explore Mojo translation across hardware targets. FLUX.2 generation via MAX is available in cloud and enterprise tiers today.