Google AI Developers
@googleaidevs
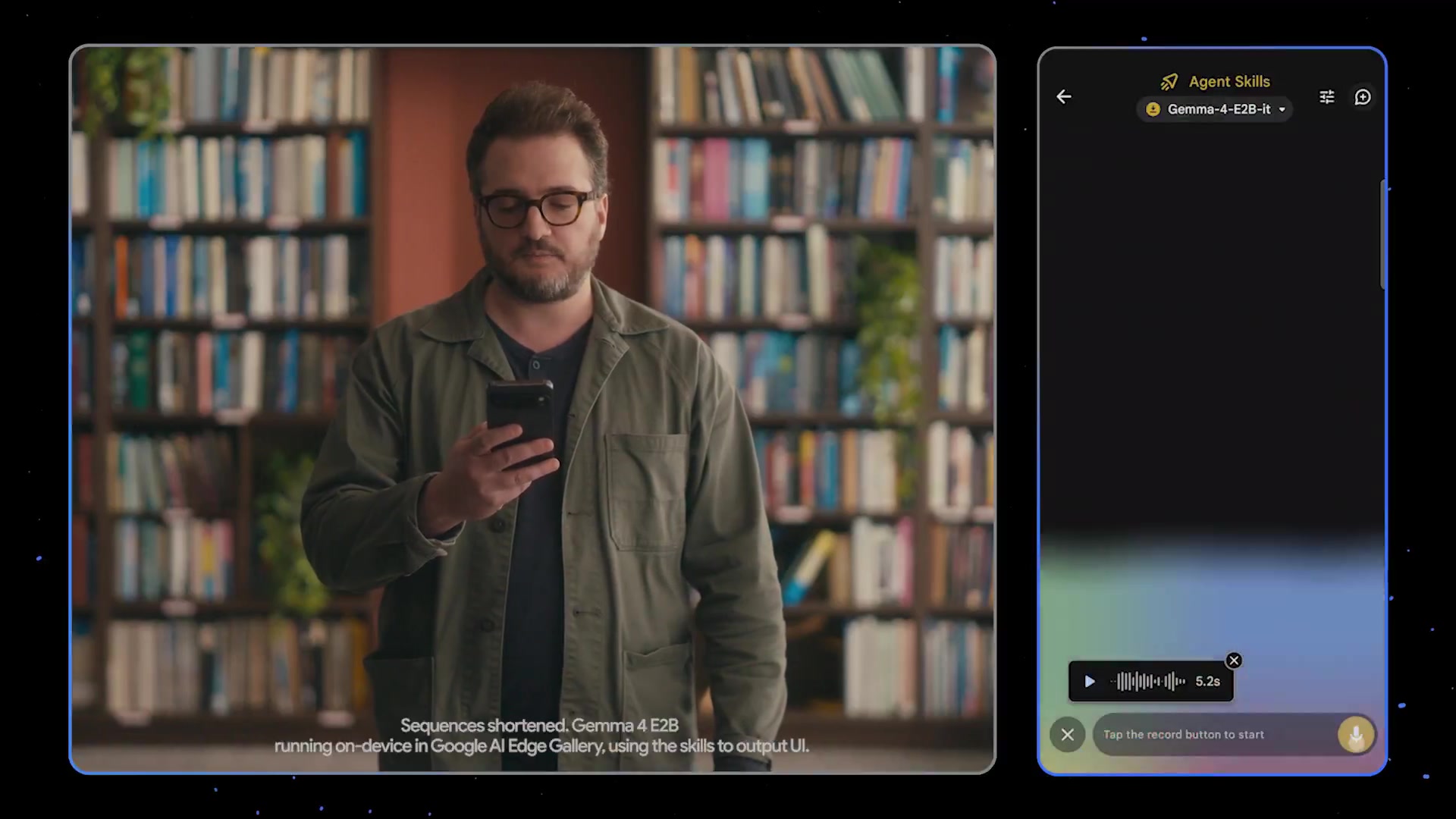
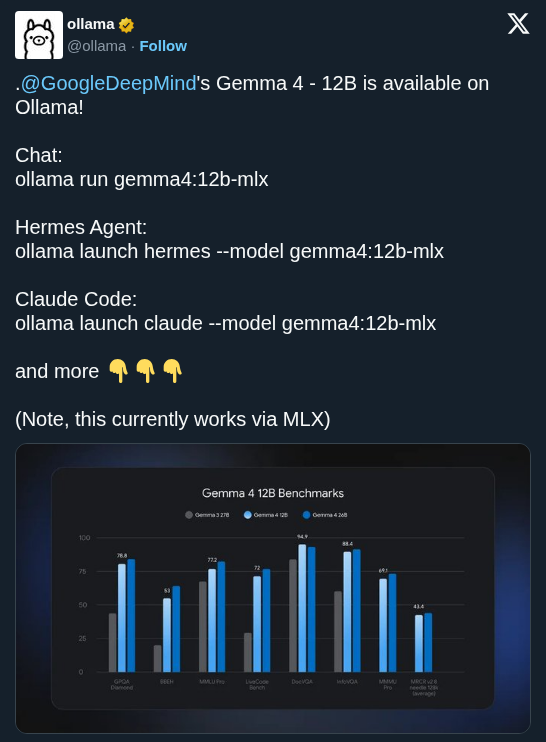
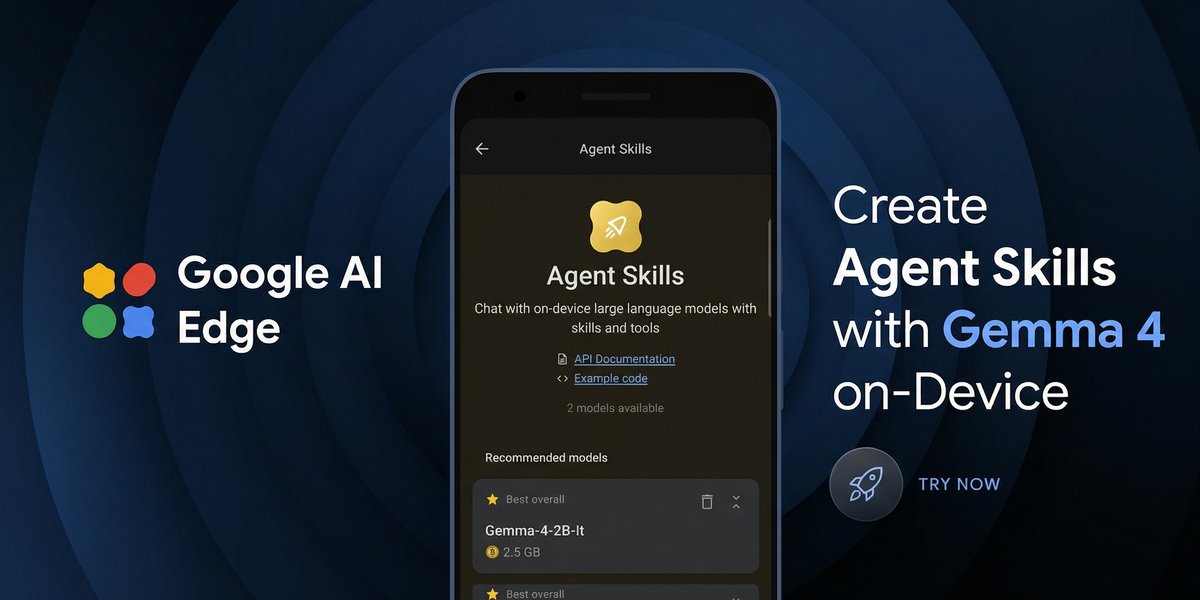
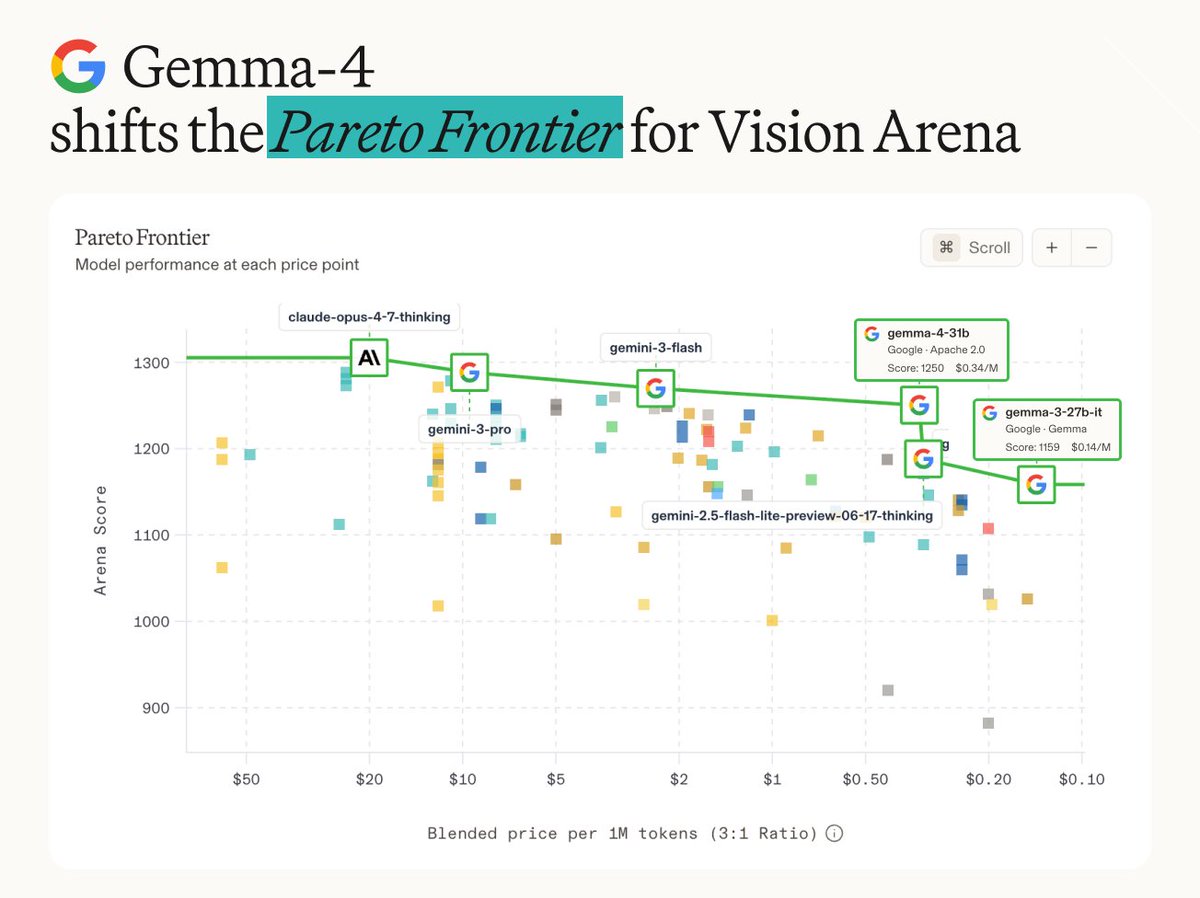
We’re launching Gemma 4 12B: Our unified, encoder-free model that brings powerful multimodal intelligence straight to your laptop 🚀 The model bridges the gap between our mobile E4B model and larger 26B MoE models, packaging frontier-class reasoning and native audio into a highly optimized footprint, all under a permissive Apache 2.0 license. Here’s what makes it unique: + Encoder-Less Architecture: We removed the multimodal encoders. The vision and audio inputs flow directly into the LLM backbone. + Agentic Performance (16GB VRAM): Run complex, multi-step workflows locally, with performance nearing our 26B model.
140retweets1.1klikes
View on X